!pip install tiktoken -qqqEstimate Cost for OpenAI Fine-Tuning
openai
Learn how to calculate the number of training tokens that will be consumed before running a fine-tuning job in OpenAI
OpenAI provides a simple approach for fine-tuning any of their chat completion models using the same messages format as regular prompting.
You provide a list of system, user, and assistant messages, and the model is fine-tuned to predict the tokens in the assistant’s message.
{
'messages': [
{'role': 'system', 'content': 'Classify text as positive or negative'},
{'role': 'user', 'content': 'cool'},
{'role': 'assistant', 'content': 'positive'}
]
}The training data is provided in a line-delimited JSON format within a .jsonl file
{"messages": [{"role": "system", "content": "Classify text as positive or negative"}, {"role": "user", "content": "cool"}, {"role": "assistant","content": "positive"}]}
{"messages": [{"role": "system", "content": "Classify text as positive or negative"}, {"role": "user", "content": "bad"}, {"role": "assistant","content": "negative"}]}
...The cost for fine-tuning is based on the number of training tokens used and provided in terms of $X/million tokens.
However, there is currently no way to determine how many training tokens will be consumed before running a fine-tuning job.
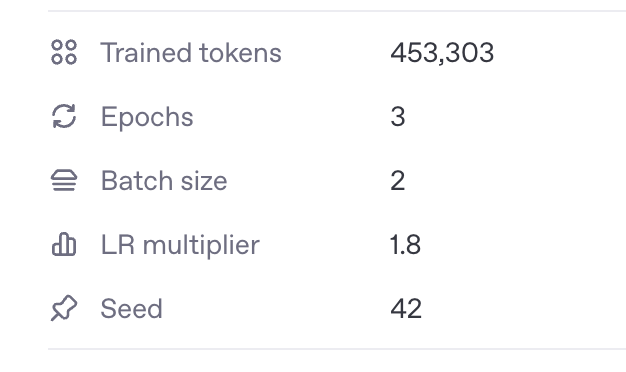
I found a way to estimate the number of tokens beforehand and have verified that this matches exactly the number of training tokens shown on the dashboard after fine-tuning.
How OpenAI counts tokens internally
Let’s take one turn of our message.
{"role": "system", "content": "Classify text as positive or negative"}Internally, this message is converted into the following format and then tokenized before being passed to the LLM. This can be tested using tiktokenizer webapp.
<|im_start|>system<|im_sep|>Classify text as positive or negative<|im_end|>Thus, each message uses three special tokens: <|im_start|> and <|im_end|> to denote beginning and end of the message and the <|im_sep|> token to separate the role and the actual content.
| part | number of tokens used |
|---|---|
| <|im_start|> | 1 |
| system | 1 |
| <|im_sep|> | 1 |
| Classify text as positive or negative | 7 |
| <|im_end|> | 1 |
| total | 11 |
The user and assistant roles also follow the same format and consume 3 extra tokens for the markers
<|im_start|>user<|im_sep|>cool<|im_end|><|im_start|>assistant<|im_sep|>positive<|im_end|>However, one additional token is consumed per assistant message, in addition to the three special tokens. It’s not clear why this extra token is charged.
Thus, the logic is that for each message, you count 3 extra tokens, add one extra if it’s the assistant role and then count the tokens for the ‘role’ and ‘content’ values using tiktoken.
Implementation of a token estimator
First, let’s install tiktoken.
We can then adapt the implementation from their cookbook to work for finetuning.
import tiktoken
def num_tokens_from_messages(messages, model="gpt-4o-mini-2024-07-18") -> int:
"""Returns the number of tokens used by a list of messages."""
SUPPORTED_MODELS = [
"gpt-3.5-turbo-0125",
"gpt-4-0314",
"gpt-4-0613",
"gpt-4-32k-0314",
"gpt-4-32k-0613",
"gpt-4o-2024-08-06",
"gpt-4o-mini-2024-07-18",
]
MODEL_ALIASES = {
"gpt-3.5-turbo": "gpt-3.5-turbo-0125",
"gpt-4o-mini": "gpt-4o-mini-2024-07-18",
"gpt-4o": "gpt-4o-2024-08-06",
"gpt-4": "gpt-4-0613",
}
# Handle model aliasing
model = MODEL_ALIASES.get(model, model)
if model not in SUPPORTED_MODELS:
raise ValueError(f"Unsupported model: {model}")
tokens_per_message = 3
try:
encoding = tiktoken.encoding_for_model(model)
except KeyError:
print(f"Warning: Model {model} not found. Using o200k_base encoding.")
encoding = tiktoken.get_encoding("o200k_base")
# Calculate token usage
total_tokens = sum(
tokens_per_message
+ (1 if msg["role"] == "assistant" else 0)
+ sum(len(encoding.encode(value)) for value in msg.values())
for msg in messages
)
return total_tokensLet’s test it out on a single training data point, assuming we are fine-tuning gpt-4o-mini.
messages = [
{"role": "system", "content": "Classify text as positive or negative"},
{"role": "user", "content": "Cool"},
{"role": "assistant", "content": "positive"},
]num_training_tokens = num_tokens_from_messages(messages, model="gpt-4o-mini-2024-07-18")
num_training_tokens22The total tokens the model sees during training is the number of training tokens multiplied by the number of epochs.
num_epochs = 3
total_tokens = num_training_tokens * num_epochs
total_tokens66The cost for fine-tuning gpt-4o-mini as of this writing is $3.00 / 1M tokens. Thus, we can calculate the final cost as the total tokens multiplied by the cost per token.
cost_per_token = 3 / 10**6
final_cost = total_tokens * cost_per_token
final_cost0.00019800000000000002Building a helper function
Let’s build a helper function to combine everything above so that we can pass the fine-tuning data and retrieve the number of training tokens.
import tiktoken
def num_tokens_from_messages(messages, model="gpt-4o-mini-2024-07-18") -> int:
"""Returns the number of tokens used by a list of messages."""
SUPPORTED_MODELS = [
"gpt-3.5-turbo-0125",
"gpt-4-0314",
"gpt-4-0613",
"gpt-4-32k-0314",
"gpt-4-32k-0613",
"gpt-4o-2024-08-06",
"gpt-4o-mini-2024-07-18",
]
MODEL_ALIASES = {
"gpt-3.5-turbo": "gpt-3.5-turbo-0125",
"gpt-4o-mini": "gpt-4o-mini-2024-07-18",
"gpt-4o": "gpt-4o-2024-08-06",
"gpt-4": "gpt-4-0613",
}
model = MODEL_ALIASES.get(model, model)
if model not in SUPPORTED_MODELS:
raise ValueError(f"Unsupported model: {model}")
tokens_per_message = 3
try:
encoding = tiktoken.encoding_for_model(model)
except KeyError:
print(f"Warning: Model {model} not found. Using o200k_base encoding.")
encoding = tiktoken.get_encoding("o200k_base")
total_tokens = sum(
tokens_per_message
+ (1 if msg["role"] == "assistant" else 0)
+ sum(len(encoding.encode(value)) for value in msg.values())
for msg in messages
)
return total_tokens
def count_finetuning_tokens(finetuning_messages, num_epochs: int = 3) -> int:
"""Returns total tokens used in fine-tuning based on training messages and epochs."""
return (
sum(num_tokens_from_messages(row["messages"]) for row in finetuning_messages)
* num_epochs
)Now we can test it on a dummy finetuning data
finetuning_jsonl_data = [
{
"messages": [
{"role": "system", "content": "Classify text as positive or negative"},
{"role": "user", "content": "cool"},
{"role": "assistant", "content": "positive"},
]
},
{
"messages": [
{"role": "system", "content": "Classify text as positive or negative"},
{"role": "user", "content": "bad"},
{"role": "assistant", "content": "negative"},
]
},
]
count_finetuning_tokens(finetuning_jsonl_data)132