A Visual Guide to ALBERT (A Lite BERT)
Consider a sentence given below. As humans, when we encounter the word “apple”, we could:
- Associate the word “apple” to our mental representation of the fruit “apple”
- Associate “apple” to the fruit rather than the company based on the context
- Understand the big picture that “he ate an apple”
- Understand it at character-level, word-level and sentence-level
The basic premise of the latest developments in NLP is to give machines the ability to learn such representations.
In 2018, Google released BERT that attempted to learn representations based on a few novel ideas:
Recap: BERT
1. Masked Language Modeling
Language modeling involves predicting the word given its context as a way to learn representation. Traditionally, this involved predicting the next word in the sentence when given previous words.

BERT instead used a masked language model objective, in which we randomly mask words in document and try to predict them based on surrounding context.

2. Next Sentence Prediction
The idea with “Next Sentence Prediction” is to detect whether two sentences are coherent when placed one after another or not.

For this, consecutive sentences from the training data are used as a positive example. For a negative example, some sentence is taken and a random sentence from another document is placed next to it. BERT model is trained on this task to identify if two sentences can occur next to each other.
3. Transformer Architecture
To solve the above two tasks, BERT uses stacked layers of transformer blocks as encoders. Word vectors are passed through the layers to capture the meaning and yield a vector of size 768 for the base model.

Jay Alammar has an excellent post that illustrates the internals of transformers in more depth.
Problems with BERT
BERT, when released, yielded state of art results on many NLP tasks on leaderboards. But, the model was very large which resulted in some issues. The “ALBERT” paper highlights these issues in two categories:
1. Memory Limitation and Communication Overhead:
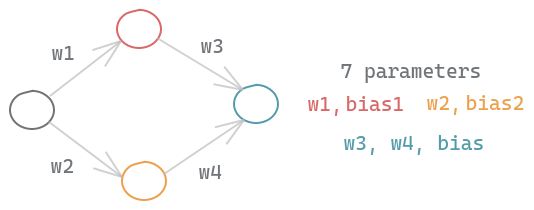
Consider a simple neural network with one input node, two hidden nodes and an output node. Even such a simple neural network will have 7 parameters to learn due to weights and bias per node.
BERT-large, being a complex model, has 340 million parameters because of its 24 hidden layers and lots of nodes in the feed-forward network and attention heads. If you wanted to build upon the work on BERT and bring improvements to it, you would require large compute requirements to train from scratch and iterate on it.

These compute requirements mainly involve GPUs and TPUs, but such devices have a memory limitation. So, there is a limit to the size of the models.
One popular approach to this problem in distributed training. Let’s take an example of data parallelism on BERT-large, where training data is divided into two machines. The model is trained on two machines on chunks of data. As shown in the figure, you can notice how a large number of parameters to transfer during the synchronization of gradients can slow down the training process. The same bottleneck applies for the model parallelism as well where we store different parts of the model(parameters) on different machines.

2. Model Degradation
The recent trend in the NLP research community is using larger and larger models to get state-of-the-art performance on leaderboards. ALBERT shows that this can have diminishing returns.
In the paper, the authors performed an interesting experiment.
If larger models lead to better performance, why not double the hidden layer units of the largest available BERT model(BERT-large) from 1024 units to 2048 units?
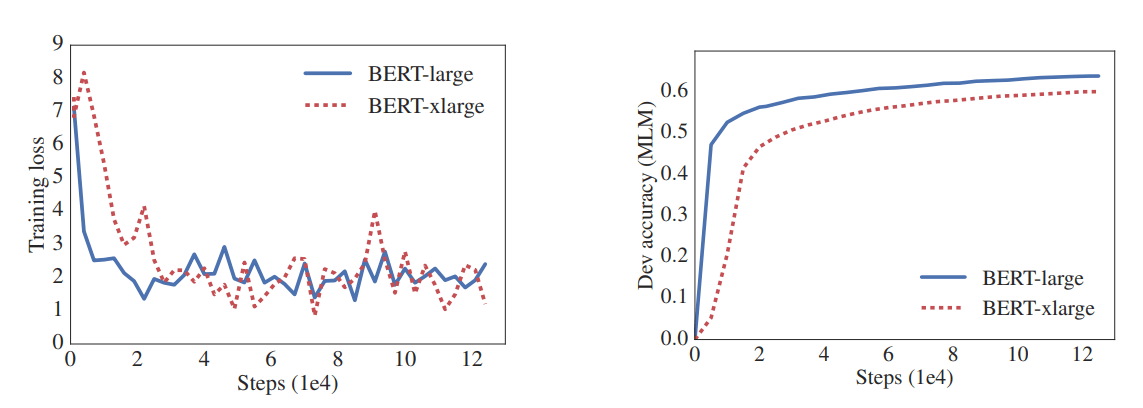
They call it “BERT-xlarge”. Surprisingly, the larger model performs worse than the BERT-large model on both the Language Modeling task as well as when tested on a reading comprehension test (RACE).

From the plots given in the original paper, we can see how the performance degrades. BERT-xlarge is performing worse than BERT-large even though it is larger and has more parameters.
From BERT to ALBERT
ALBERT attacks these problems by building upon on BERT with a few novel ideas:
1. Cross-layer parameter sharing
BERT large model had 24 layers while it’s base version had 12-layers. As we add more layers, we increase the number of parameters exponentially.
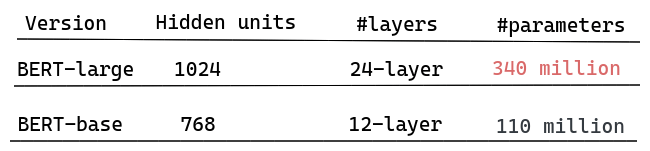
To solve this problem, ALBERT uses the concept of cross-layer parameter sharing. To illustrate, let’s see the example of a 12-layer BERT-base model. Instead of learning unique parameters for each of the 12 layers, we only learn parameters for the first block and reuse the block in the remaining 11 layers.

We can share parameters for either feed-forward layer only, the attention parameters only or share the parameters of the whole block itself. The paper shares the parameters for the whole block.
Compared to the 110 million parameters of BERT-base, the ALBERT model only has 31 million parameters while using the same number of layers and 768 hidden units. The effect on accuracy is minimal for embedding size of 128. A major drop in accuracy is due to feed-forward network parameter sharing. The effect of sharing attention parameters is minimal.

2. Sentence-Order Prediction (SOP)
BERT introduced a binary classification loss called “Next Sentence Prediction”. This was specifically created to improve performance on downstream tasks that use sentence pairs like “Natural Language Inference”. The basic process is:
- Take two segments that appear consecutively from the training corpus
- Create a random pair of segments from the different document as negative examples
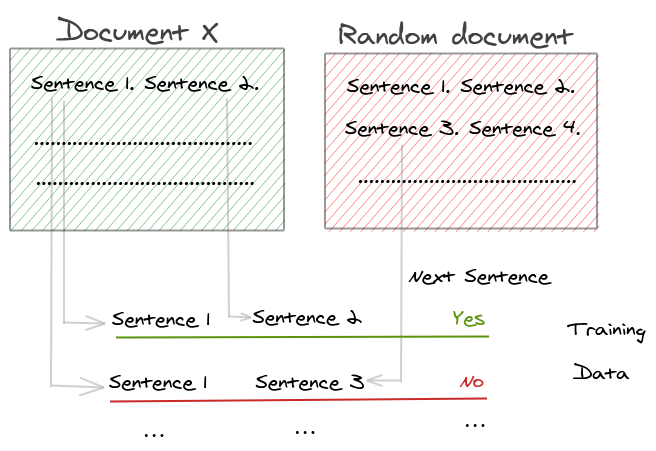
Papers like ROBERTA and XLNET have shed light on the ineffectiveness of NSP and found its impact on the downstream tasks unreliable. On eliminating the NSP task, the performance across several tasks improved.
So, ALBERT proposes an alternative task called “Sentence Order Prediction”. The key idea is:
- Take two consecutive segments from the same document as a positive class
- Swap the order of the same segment and use that as a negative example
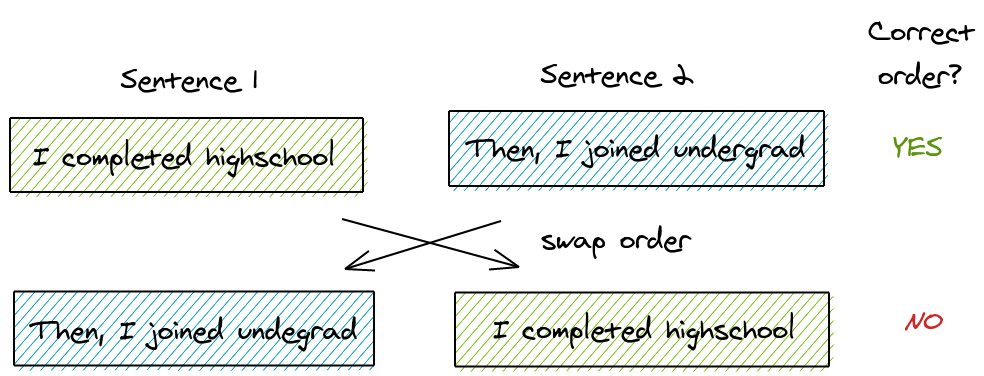
This forces the model to learn finer-grained distinction about discourse-level coherence properties.
ALBERT conjectures that NSP was ineffective because it’s not a difficult task when compared to masked language modeling. In a single task, it mixes both topic prediction and coherence prediction. The topic prediction part is easy to learn because it overlaps with the masked language model loss. Thus, NSP will give higher scores even when it hasn’t learned coherence prediction.
SOP improves performance on downstream multi-sentence encoding tasks (SQUAD 1.1, 2.0, MNLI, SST-2, RACE).

Here we can see how a model trained on NSP is only giving scores slightly better than the random baseline on the SOP task, but model trained on SOP can solve the NSP task quite effectively. This provides evidence that SOP leads to better learning representation.
3. Factorized embedding parameterization
In BERT, the embeddings used (word piece embeddings) size was linked to the hidden layer sizes of the transformer blocks. Word piece embeddings learned from the one-hot encoding representations of a vocabulary of size 30,000 was used. These are projected directly to the hidden space of the hidden layer.
Let’s say we have a vocabulary of size 30K, word-piece embedding of dimension E=768 and a hidden layer of size H=768. If we increase hidden units in the block, then we need to add a new dimension to each embedding as well. This problem is prevalent in XLNET and ROBERTA as well.
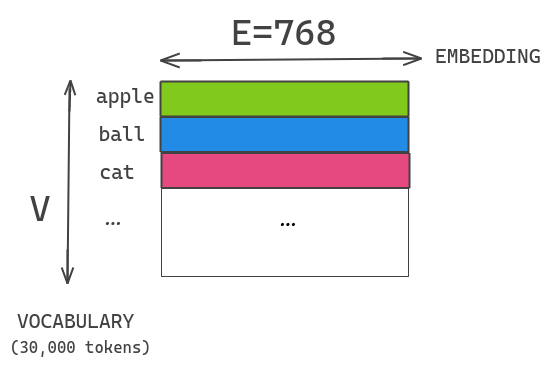
ALBERT solves this problem by factorizing the large vocabulary embedding matrix into two smaller matrices. This separates the size of the hidden layers from the size of the vocabulary embeddings. This allows us to grow the hidden size without significantly increasing the parameter size of the vocabulary embeddings.
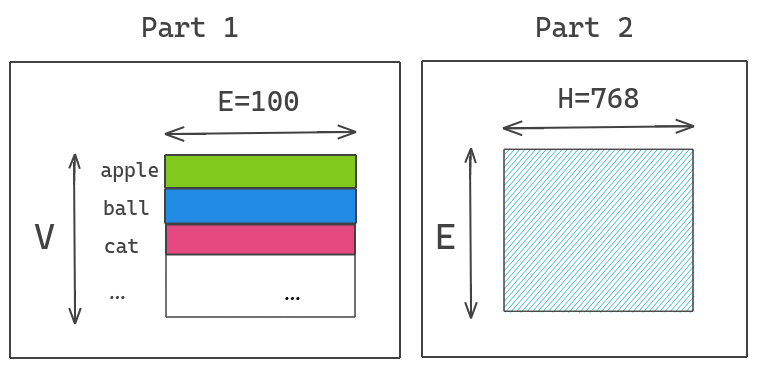
We project the One Hot Encoding vector into the lower dimension embedding space of E=100 and then this embedding space into the hidden space H=768.
Results
- 18x fewer parameters than BERT-large
- Trained 1.7x faster
- Got SOTA results on GLUE, RACE and SQUAD during its release
- RACE: 89.4% (+45.3% improvement)
- GLUE Benchmark: 89.4
- SQUAD 2.0 F1-score: 92.2
Conclusion
ALBERT marks an important step towards building language models that not only get SOTA on the leaderboards but are also feasible for real-world applications.
References
Citation
@online{chaudhary2020,
author = {Chaudhary, Amit},
title = {A {Visual} {Guide} to {ALBERT} {(A} {Lite} {BERT)}},
date = {2020-02-08},
url = {https://amitness.com/posts/albert-visual-summary.html},
langid = {en}
}