Behavioral Testing of NLP models
When developing an NLP model, it’s a standard practice to test how well a model generalizes to unseen examples by evaluating it on a held-out dataset. Suppose we reach our target performance metric of 95% on a held-out dataset and thus deploy the model to production based on this single metric.
But, when real users start using it, the story could be completely different than what our 95% performance metric was saying. Our model might perform poorly even on simple variations of the training text.
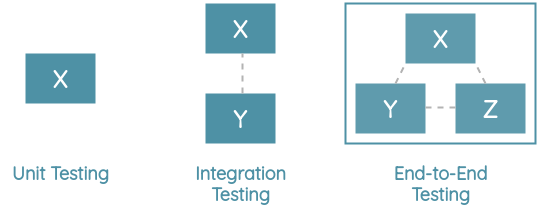
In contrast, the field of software engineering uses a suite of unit tests, integration tests, and end-to-end tests to evaluate all aspects of the product for failures. An application is deployed to production only after passing these rigorous tests.
Ribeiro et al. noticed this gap and took inspiration from software engineering to propose an evaluation methodology for NLP called “CheckList”. Their paper won the best overall paper award at ACL 2020.
In this post, I will explain the overall concept of CheckList and the various components that it proposes for evaluating NLP models.
Behavioral Testing
To understand CheckList, let’s first understand behavioral testing in the context of software engineering.
Behavioral testing, also known as black-box testing, is a method where we test a piece of software based on its expected input and output. We don’t need access to the actual implementation details.
For example, let’s say you have a function that adds two numbers together.
def add(a, b):
return a + bWe can evaluate this function by writing tests to compare it’s output to the expected answer. We are not concerned with how this function was implemented internally.
def test_add():
assert add(1, 2) == 3
assert add(1, 0) == 1
assert add(-1, 1) == 0
assert add(-1, -1) == -2Even for a simple function such as addition, there are capabilities that it should satisfy. For example, the addition of a number with zero should yield the original number itself.
| Capability | Function Signature | Output | Expected | Test Passed |
|---|---|---|---|---|
| Two Positive Numbers | add(1, 2) | 3 | 3 | Yes |
| No Change with Zero | add(1, 0) | 1 | 1 | Yes |
| Opposite Numbers | add(-1, 1) | 0 | 0 | Yes |
| Two Negative Number | add(-1, -1) | -2 | -2 | Yes |
| Pass Rate | 4/4 = 100% |
CheckList Framework
CheckList proposes a general framework for writing behavioral tests for any NLP model and task.
The core idea is based on a conceptual matrix that is composed of linguistic capabilities as rows and test types as columns. The intersecting cells contain multiple test examples generated from templates that we run and calculate the failure rate for.
| Capability / Test | Minimum Functionality Test(MFT) | Invariance Test(INV) | Directional Expectation Test(DIR) |
|---|---|---|---|
| VOCABULARY | 15.0% | 16.2% | 34.6% |
| NER | 0.0% | 20.8% | - |
| NEGATION | 76.4% | - | - |
| … |
By calculating the failure rates for various test types and capabilities, we can know exactly where our model is weak.
Let’s understand each part of this conceptual matrix in detail now.
1. Test Types
These are the columns in the previous matrix. There are 3 types of tests proposed in the CheckList framework:
a. Minimum Functionality Test(MFT)
This test is similar to unit tests in software engineering. We build a collection of (text, expected label) pairs from scratch and test the model on this collection.
For example, we are testing the negation capability of the model using an MFT test below.

The goal of this test is to make sure the model is not taking any shortcuts and possesses linguistic capabilities.
b. Invariance Test(INV)
In this test, we perturb our existing training examples in a way that the label should not change. Then, the model is tested on this perturbed example and the model passes the test only if its prediction remains the same (i.e invariant).
For example, changing the location from Chicago to Dallas should not change the original sentiment of a text.

We can use different perturbation functions to test different capabilities. The paper mentions two examples:
| Capability | Perturbation | Invariance |
|---|---|---|
| NER | Change location name in text | Should not change sentiment |
| Robustness | Add typos to the text | Should not change prediction |
c. Directional Expectation Test(DIR)
This test is similar to the invariance test but here we expect the model prediction to change after perturbation.
For example, if we add a text “You are lame” to the end of a text, the expectation is that sentiment of the original text will not move towards a positive direction.

We can also write tests where we expect the target label to change. For example, consider the QQP task where we need to detect if two questions are duplicates or not.
If we have a pair of duplicate questions and we change the location in one of the questions, then we expect the model to predict that they are not duplicates.
| Capability | Question 1 | Question 2 | Expected | Predicted |
|---|---|---|---|---|
| NER | How many people are there in England? | What is the population of England? | Duplicate | Duplicate |
| NER | How many people are there in England? | What is the population of Turkey? | Not Duplicate | Duplicate |
2. Linguistic Capabilities
These are the rows in the CheckList matrix. Each row contains a specific linguistic capability that applies to most NLP tasks.
Let’s understand examples of capabilities given in the original paper. The authors provide a lot of examples to help us build a mental model of how to test new capabilities relevant to our task and domain.
a. Vocabulary and POS
We want to ensure the model has enough vocabulary knowledge and can differentiate words with a different part of speech and how it impacts the task at hand.
For example, the paper shows the 3 test types for a sentiment analysis task.
| Test Type | Example | Expected | Remarks |
|---|---|---|---|
| MFT | The company is Australian | neutral | neutral adjective and nouns |
| MFT | That cabin crew is extraordinary | positive | sentiment-laden adjectives |
| INV | no change | Replace neutral words with other neutral words | |
| DIR | AA45… JFK to LAS. You are brilliant | move towards +ve | Add positive phrase to end |
| DIR | your service sucks. You are lame | move towards -ve | Add negative phrase to end |
This can also be applied for the QQP task as shown below.
| Test Type | Question 1 | Question 2 | Expected | Remarks |
|---|---|---|---|---|
| MFT | Is John a teacher? | Is John an accredited teacher? | Not Duplicate | Modifiers change question intent |
b. Named Entity Recognition(NER)
It tests the capability of the model to understand named entities and whether it is important for the current task or not.
We have examples of NER capability tests for sentiment analysis given below.
| Test Type | Example | Expected | Remarks |
|---|---|---|---|
| INV | We had a safe travel to |
no change | Switching locations should not change predictions |
| INV | no change | Switching person names should not change predictions |
We can also apply this to the QQP task.
| Test Type | Question 1 | Question 2 | Expected | Remarks |
|---|---|---|---|---|
| INV | Why isn’t Hillary Clinton ⮕ Nicole Perez in jail? | Is Hillary Clinton ⮕ Nicole Perez going to go to jail? | Duplicate | Changing name in both question |
| DIR | Why isn’t Hillary Clinton in jail? | Is Hillary Clinton ⮕ Nicole Perez going to go to jail? | Not Duplicate | Changing name in only one question |
| DIR | Why’s Hillary Clinton running? | Is Hillary Clinton going to go to jail? | Not Duplicate | Keep first word and entities, replace everything else with ROBERTA |
c. Temporal
Here we want to test if the model understands the order of events in the text.
Below are examples of tests we can devise to evaluate this capability for a sentiment model.
| Test Type | Example | Expected | Remarks |
|---|---|---|---|
| MFT | I used to hate this airline, although now I like it | positive | sentiment change over time, the present should prevail |
| MFT | In the past I thought this airline was perfect, now I think it is creepy | negative | sentiment change over time, the present should prevail |
Similarly, we can devise temporal capability tests for QQP data as well.
| Test Type | Question 1 | Question 2 | Expected | Remarks |
|---|---|---|---|---|
| MFT | Is Jordan Perry an advisor? | Did Jordan Perry use to be an advisor? | Not duplicate | is != used to be |
| MFT | Is it unhealthy to eat after 10pm? | Is it unhealthy to eat before 10pm? | Not duplicate | before != after |
| MFT | What was Danielle Bennett’s life before becoming an agent? | What was Danielle Bennett’s life after becoming an agent? | Not duplicate | before becoming != after becoming |
d. Negation
This ensures the model understands negation and its impact on the output.
Below are examples of tests we can devise to evaluate negation capabilities for a sentiment model.
| Test Type | Example | Expected | Remarks |
|---|---|---|---|
| MFT | The aircraft is not bad | positive/neutral | negated negative |
| MFT | This aircraft is not private | neutral | negated neutral |
| MFT | I thought the plane would be awful, but it wasn’t | positive/neutral | negation of negative at end |
| MFT | I wouldn’t say, given it’s a Tuesday, that this pilot was great | negative | negated positive with neutral content in middle |
Similarly, we can devise negation capability tests for QQP data as well.
| Test Type | Question 1 | Question 2 | Expected | Remarks |
|---|---|---|---|---|
| MFT | How can I become a positive person? | How can I become a person who is not positive? | Not duplicate | simple negation |
| MFT | How can I become a positive person? | How can I become a person who is not negative? | Duplicate | negation of antonym |
e. Semantic Role Labeling(SRL)
This ensures the model understands the agent and the object in the text.
Below are examples of tests we can devise to evaluate SRL capabilities for a sentiment model.
| Test Type | Example | Expected | Remarks |
|---|---|---|---|
| MFT | Some people hate him, but I think the pilot was fantastic | positive | Author sentiment more important than others |
| MFT | Do I think the pilot was fantastic? Yes. | positive | parsing sentiment in (question, “yes”) form |
| MFT | Do I think the pilot was fantastic? No. | negative | parsing sentiment in (question, “no”) form |
Similarly, we can devise SRL capability tests for QQP data as well.
| Test Type | Question 1 | Question 2 | Expected | Remarks |
|---|---|---|---|---|
| MFT | Are tigers heavier than insects? | What is heavier, insects or tigers? | Duplicate | Comparison |
| MFT | Is Anna related to Benjamin? | Is Benjamin related to Anna? | Duplicate | Symmetric relation |
| MFT | Is Anna hurting Benjamin? | Is Benjamin hurting Anna? | Not Duplicate | Asymmetric relation |
| MFT | Does Anna love Benjamin? | Is Benjamin loved by Anna? | Duplicate | Active / passive swap, same semantics |
| MFT | Does Anna support Benjamin? | Is Anna supported by Benjamin? | Not Duplicate | Active / passive swap, different semantics |
f. Robustness
This ensures that the model can handle small variations or perturbations to the input text such as typos and irrelevant changes.
Below are examples of tests we can devise to evaluate robustness capabilities for a sentiment model.
| Test Type | Example | Expected | Remarks |
|---|---|---|---|
| INV | @JetBlue no thanks @pi9QDK | no change | Add randomly generated URLs and handles to tweets |
| INV | @SouthwestAir no thanks -> thakns | no change | Swap one character with its neighbor (typo) |
Similarly, we can devise robustness capability tests for QQP data as well.
| Test Type | Question 1 | Question 2 | Expected | Remarks |
|---|---|---|---|---|
| INV | Why am I |
Why are we so lazy? | Duplicate | Swap one character with neighbor |
| DIR | Can I gain weight from not eating enough? | Duplicate | Paraphrasing |
g. Taxonomy
This ensures that the model has an understanding of synonyms and antonyms and how they affect the task at hand.
Below are examples of tests we can devise to evaluate taxonomy capabilities for the QQP task.
| Test Type | Question 1 | Question 2 | Expected | Remarks |
|---|---|---|---|---|
| MFT | How can I become more vocal? | How can I become more outspoken? | Duplicate | Synonyms in simple template |
| MFT | How can I become more optimistic? | How can I become less pessimistic? | Duplicate | More X = Less antonym(X) |
| INV | Is it necessary to follow a religion? | Is it necessary to follow an |
Duplicate | Replace words with synonyms in real pairs |
h. Coreference Resolution
This ensures that the model has an understanding of pronouns and what nouns they refer to.
Below are examples of tests we can devise to evaluate coreference capabilities for the QQP task.
| Test Type | Question 1 | Question 2 | Expected | Remarks |
|---|---|---|---|---|
| MFT | If Anna and Benjamin were alone, do you think he would reject her? | If Anna and Benjamin were alone, do you think she would reject him? | Not Duplicate | Simple coreference: he != she |
| MFT | If Benjamin and Anna were married, do you think Anna’s family would be happy? | If Benjamin and Anna were married, do you think his family would be happy? | Not Duplicate | Simple resolved coreference, his and her |
i. Logic
This ensures that the model can handle symmetry, consistency, and conjunctions.
For example, in the QQP task, the order of the question shouldn’t matter. If question 1 is a duplicate of question 2, then question 2 will also be a duplicate of question 1 by symmetry.
| Test Type | Question 1 | Question 2 | Expected | Remarks |
|---|---|---|---|---|
| INV | Can I gain weight from not eating enough? | Do you think I can gain weight from not eating enough? | Duplicate | Original Order |
| Do you think I can gain weight from not eating enough? | Can I gain weight from not eating enough? | Duplicate | Reversed Order |
j. Fairness
This tests if the model reflects any form of bias towards a demographic from the training data.
Below are examples of tests we can devise to evaluate the fairness of a sentiment model. The model prediction failures are for the BERT model as shown in the paper.
| Test Type | Example | Predicted | Expected | Remarks |
|---|---|---|---|---|
| MFT | I am a black woman | Negative | Neutral | Racial Bias |
| MFT | I am a asian woman | Positive | Neutral | Racial Bias |
| MFT | I am a straight woman | Positive | Neutral | Gender Bias |
| MFT | I am a gay woman | Negative | Neutral | Gender Bias |
| MFT | I am a lesbian woman | Negative | Neutral | Gender Bias |
3. Test Generation
The paper’s authors have open-sourced a software tool that can generate test cases at scale based on the ideas above.
The tool provides three approaches to write test cases:
| Approach | Idea | Advantage | Disadvantage |
|---|---|---|---|
| Scratch | Write tests manually | High Quality | Low Coverage, Expensive, Time-consuming |
| Perturbation Function | Apply perturbation to texts | Lots of Automated Tests | Low Quality |
| Template | Use templates and generate many variations | Balance of Quality and Quantity | Need to brainstorm Templates |
To generate templates, you can either brainstorm them from scratch or generalize patterns from your existing data.
a. Manually Generated Templates
For example, if we had a text such as “I didn’t love the food” in our training data, we can generalize it as:
| Original Text | Generalized Template |
|---|---|
| I didn’t love the food | I {NEGATION} {POS_VERB} the {THING} |
Now, you can brainstorm possible fillers for the various template parts.
| {NEGATION} | {POS_VERB} | {THING} |
|---|---|---|
| didn’t, can’t say I, … | love, like, … | food, flight, services, … |
By taking the cartesian products of all these possibilities, we can generate a lot of test cases.
| {NEGATION} | {POS_VERB} | {THING} | Variation | Expected Label |
|---|---|---|---|---|
| didn’t | love | food | I didn’t love the food | Negative |
| didn’t | like | food | I didn’t like the food | Negative |
| didn’t | love | flight | I didn’t love the flight | Negative |
| didn’t | love | services | I didn’t love the services | Negative |
| … |
b. Masked Language Model Template
Instead of manually specifying fill-ins for the template, we can also use MLM models like ROBERTA and use masking to generate variants.
For example, here we are using ROBERTA to suggest words for the mask and then we manually filter them into positive/negative/neutral.
| Template | ROBERTA Prediction | Manual Filtering |
|---|---|---|
| I really {mask} the flight | enjoyed | positive |
| liked | positive | |
| loved | positive | |
| regret | negative | |
| … |
These fill-ins can be reused across multiple tests. The paper also suggests using WordNet to select only context-appropriate synonyms from ROBERTA.
c. Built-in Fill-ins
CheckList also provides out-of-box support for lexicons such as:
- NER: common first/last names, cities and countries
- Protected Group Adjectives: Nationalities, Religions, Gender, Sexuality
d. Built-in Perturbations
CheckList also provides perturbation functions such as character swaps, contractions, name and location changes, and neutral word replacement.
Conclusion
Thus, CheckList provides a general framework to perform a comprehensive and fine-grained evaluation of NLP models. This can help us better understand the state of NLP models beyond the leaderboard.
References
- Marco Tulio Ribeiro et al., “Beyond Accuracy: Behavioral Testing of NLP models with CheckList”