Knowledge Transfer in Self Supervised Learning
Self Supervised Learning is an interesting research area where the goal is to learn rich representations from unlabeled data without any human annotation.
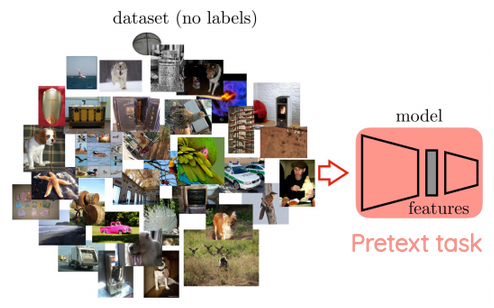
This can be achieved by creatively formulating a problem such that you use parts of the data itself as labels and try to predict that. Such formulations are called pretext tasks.
For example, you can setup a pretext task to predict the color version of the image given the grayscale version. Similarly, you could remove a part of the image and train a model to predict the part from the surrounding. There are many such pretext tasks.

By pre-training on the pretext task, the hope is that the model will learn useful representations. Then, we can finetune the model to downstream tasks such as image classification, object detection, and semantic segmentation with only a small set of labeled training data.
Challenge of evaluating representations
So pretext tasks can help us learn representations. But, this poses a question:
How to determine how good a learned representation is?
Currently, the standard way to gauge the representations is to evaluate it on a set of standard tasks and benchmark datasets.
- Linear classification: ImageNet classification using frozen features
- Low Data Regime: ImageNet Classification using only 1% to 10% of data
- Transfer Learning: Object Classification, Object Detection and Semantic Segmentation on PASCAL VOC
We can see that the above evaluation methods require us to use the same model architecture for both the pretext task and the target task.
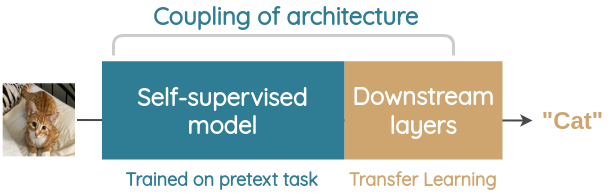
This poses some interesting challenges:
For the pretext task, our goal is to learn on a large-scale unlabeled dataset and thus deeper models(e.g. ResNet) would help us learn better representations. But, for downstream tasks, we would prefer shallow models(e.g. AlexNet) for actual applications. Thus, we currently have to consider this limitation when designing the pretext task.
It’s harder to fairly compare which pre-text task is better if some methods used simpler architecture while other methods used deeper architecture.
We can’t compare the representations learned from pretext tasks to handcrafted features such as HOG.
We may want to exploit several data domains such as sound, text, and videos in the pretext task but the target task may limit our design choices.
Model trained on pretext task may learn extra knowledge that is not useful for generic visual recognition. Currently, the final task-specific layers are ignored and weights or features only up to certain convolutional layers are taken.
Knowledge Transfer
Noroozi et al. (2018) proposed a simple idea to tackle these issues in their 2018 paper “Boosting Self-Supervised Learning via Knowledge Transfer”.
Intuition
The authors observed that in a good representation space, semantically similar data points should be close together.

In regular supervised classification, the information that images are semantically similar is encoded through labels annotated by humans. A model trained on such labels would have a representation space that groups semantically similar images.
Thus, with pre-text tasks in self-supervised learning, the objective is implicitly learning a metric that makes the same category images similar and different category images dissimilar. Hence we can provide a robust estimate of the learned representation if we could encode semantically related images to the same labels in some way.
General Framework
The authors propose a novel framework to transfer knowledge from a deep self-supervised model to a separate shallow downstream model. You can use different model architectures for the pretext task and downstream task.
Key Idea:
Cluster features from pretext task and assign cluster centers as pseudo-labels for unlabeled images. Then, re-train a small network with target task architecture on pseudo-labels to predict pseudo-labels and learn a novel representation.
The end-to-end process is described below:
1. Pretext task
Here we choose some deep network architecture and train it on some pretext task of our choice on some dataset. We can take features from some intermediate layer after the model is trained.
2. K-means Clustering
For all the unlabeled images in the dataset, we compute the feature vectors from the pretext task model. Then, we run K-means clustering to group semantically similar images. The idea is that the cluster centers will be aligned with categories in ImageNet.
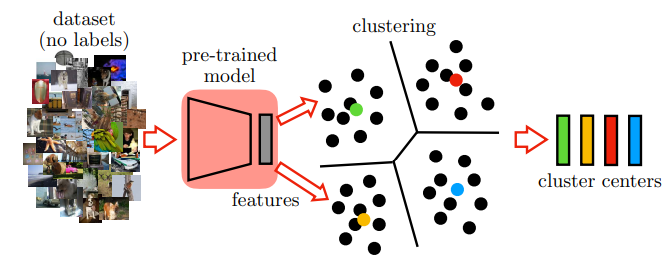
In the paper, the authors ran K-means on a single Titan X GPU for 4 hours to cluster 1.3M images into 2000 categories.
3. Pseudo-labeling
The cluster centers are treated as the pseudo-label. We can use either the same dataset as the above step or use a different dataset itself. Then, we compute the feature vectors for those images and find the closest cluster center for each image. This cluster center is used as the pseudo-label.
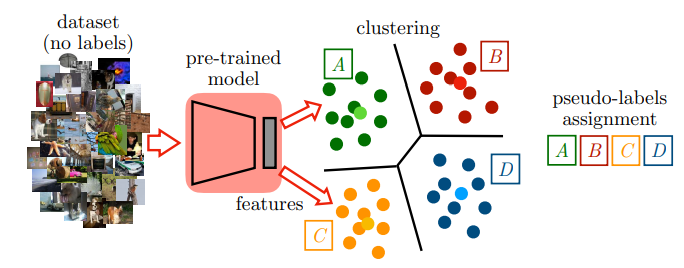
4. Training on Pseudo-labels
We take the model architecture that will be used for downstream tasks and train it to classify the unlabeled images into the pseudo-labels. Thus, the target architecture will learn a new representation such that it will map images that were originally close in the pre-trained feature space to close points.
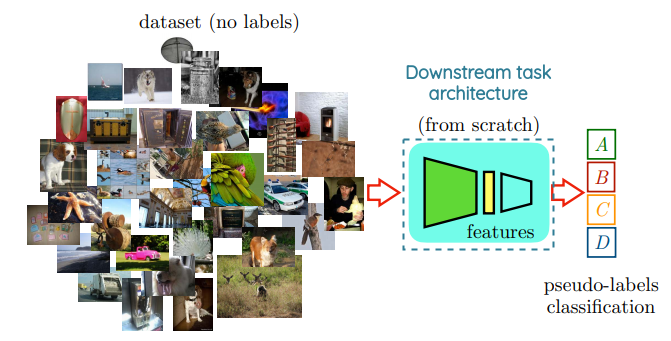
Advantage of Knowledge Transfer
We saw how by clustering the features and then using pseudo-labels, we can bring the knowledge from any pretext task representations into a common reference model like AlexNet.
As such, we can now easily compare different pretext tasks even if they are trained using different architectures and on different data domains. This also allows us to improve self-supervised methods by using deep models and challenging pretext tasks.
How well does this framework work?
To evaluate the idea quantitatively, the authors set up an experiment as described below:
a. Increase complexity of pretext task (Jigsaw++)
To evaluate their method, the authors took an old puzzle-like pretext task called “Jigsaw” where we need to predict the permutation that was used to randomly shuffle a 3*3 square grid of image.

They extended the task by randomly replacing 0 to 2 number of tiles with tile from another random image at some random locations. This increases the difficulty as now we need to solve the problem using only the remaining patches. The new pretext task is called “Jigsaw++”.
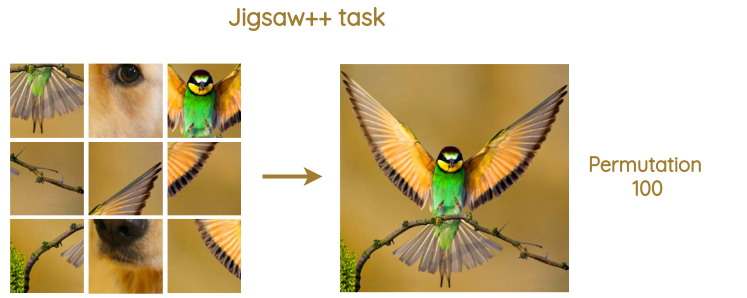
In the paper, they use 701 total permutations which had a minimum hamming distance of 3. They apply mean and standard deviation normalization at each image tile independently. They also make images gray-scale 70% of the time to prevent the network from cheating with low-level statistics.
b. Use a deeper network to solve pretext task
The authors used VGG-16 to solve the pretext task and learn representations. As VGG-16 has increased capacity, it can better handle the increased complexity of the “Jigsaw++” task and thus extract better representation.
c. Transfer Knowledge back to AlexNet
The representations from VGG-16 are clustered and cluster centers are converted to pseudo-labels. Then, AlexNet is trained to classify the pseudo-labels.
d. Finetune AlexNet on Evaluation datasets
For downstream tasks, the convolutional layers for the AlexNet model are initialized with weights from pseudo-label classification and the fully connected layers were randomly initialized. The pre-trained AlexNet is then finetuned on various benchmark datasets.
e. Results
Using a deeper network like VGG-16 leads to better representation and pseudo-labels and also better results in benchmark tasks. It got state of the art results on several benchmarks in 2018 and reduced the gap between supervised and self-supervised methods further.
1. Transfer Learning on PASCAL VOC
The authors tested their method on object classification and detection on PASCAL VOC 2007 dataset and semantic segmentation on PASCAL VOC 2012 dataset.
- Training Jigsaw++ with VGG16 and using AlexNet to predict cluster gives the best performance.
- Switching to a challenging pretext task “Jigsaw++” improves performance than “Jigsaw”.
- Knowledge transfer doesn’t have a significant impact when using the same architecture AlexNet in both Jigsaw++ and downstream tasks.
| Task | Cluster | Pretext | Downstream | Classification | Detection(SS) | Detec.(MS) | Segmentation |
|---|---|---|---|---|---|---|---|
| Jigsaw | no | AlexNet | AlexNet | 67.7 | 53.2 | - | - |
| Jigsaw++ | no | AlexNet | AlexNet | 69.8 | 55.5 | 55.7 | 38.1 |
| Jigsaw++ | yes | AlexNet | AlexNet | 69.9 | 55.0 | 55.8 | 40.0 |
| Jigsaw++ | yes | VGG-16 | AlexNet | 72.5 | 56.5 | 57.2 | 42.6 |
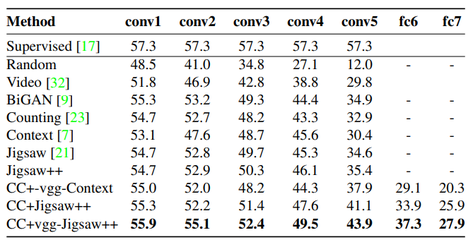
2. Linear Classification on ImageNet
In this, a linear classifier is trained on features extracted from AlexNet at different convolutional layers. For ImageNet, using VGG-16 and transferring knowledge to AlexNet using clustering gives a substantial boost of 2%.
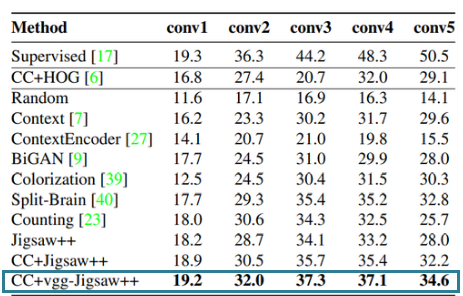
3. Non-linear classification on ImageNet
For a non-linear classifier, using VGG-16 and transferring knowledge to AlexNet using clustering gives the best performance on ImageNet.
Additional Insights from Paper
1. How does the number of clusters affect the performance?
The network is not significantly affected by the number of clusters. The authors tested AlexNet trained on pseudo-labels from a different number of clusters on the task of object detection.

2. How is this different from Knowledge Distillation?
Knowledge transfer is fundamentally different from knowledge distillation. Here, the goal is to only preserve the cluster association of images from the representation and transfer that to the target model. Unlike distillation, we don’t do any regression to the exact output of the teacher.
3. Can you use different datasets in clustering vs predicting pseudo-labels?
Yes, the method is flexible and you can pre-train on one dataset, cluster on another, and get pseudo-labels for the third one.
The authors did an experiment where they trained clustering on representations for ImageNet and then calculated cluster centers on the “Places” dataset to get pseudo-labels. There was only a small reduction (-1.5%) in performance for object classification.

Conclusion
Thus, Knowledge Transfer is a simple and efficient way to map representations from deep to shallow models.