Self Supervised Representation Learning in NLP
While Computer Vision is making amazing progress on self-supervised learning only in the last few years, self-supervised learning has been a first-class citizen in NLP research for quite a while. Language Models have existed since the 90’s even before the phrase “self-supervised learning” was termed. The Word2Vec paper from 2013 popularized this paradigm and the field has rapidly progressed applying these self-supervised methods across many problems.
At the core of these self-supervised methods lies a framing called “pretext task” that allows us to use the data itself to generate labels and use supervised methods to solve unsupervised problems. These are also referred to as “auxiliary task” or “pre-training task”. The representations learned by performing this task can be used as a starting point for our downstream supervised tasks.
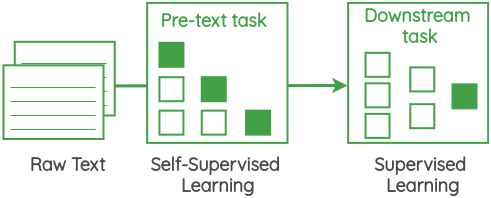
In this post, I will provide an overview of the various pretext tasks that researchers have designed to learn representations from text corpus without explicit data labeling. The focus of the article will be on the task formulation rather than the architectures implementing them.
Self-Supervised Formulations
1. Center Word Prediction
In this formulation, we take a small chunk of the text of a certain window size and our goal is to predict the center word given the surrounding words.
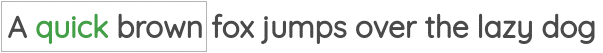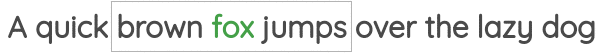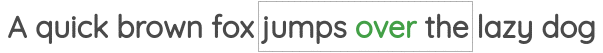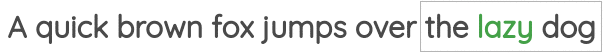
For example, in the below image, we have a window of size of one and so we have one word each on both sides of the center word. Using these neighboring words, we need to predict the center word.

This formulation has been used in the famous “Continuous Bag of Words” approach of the Word2Vec paper.
2. Neighbor Word Prediction
In this formulation, we take a span of the text of a certain window size and our goal is to predict the surrounding words given the center word.
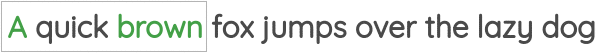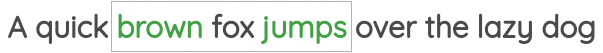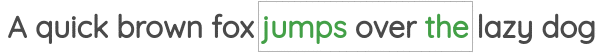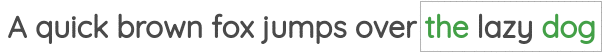
This formulation has been implemented in the famous “skip-gram” approach of the Word2Vec paper.
3. Neighbor Sentence Prediction
In this formulation, we take three consecutive sentences and design a task in which given the center sentence, we need to generate the previous sentence and the next sentence. It is similar to the previous skip-gram method but applied to sentences instead of words.
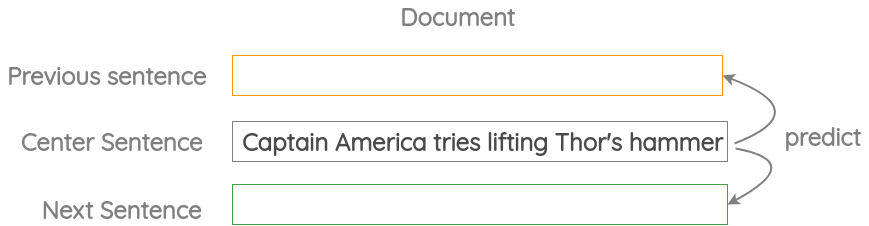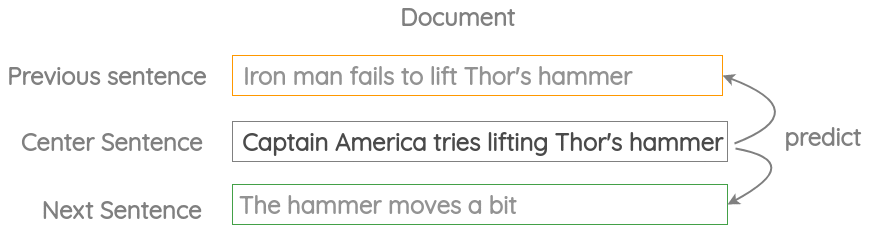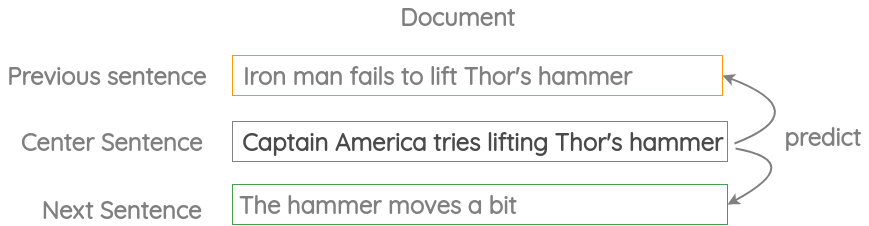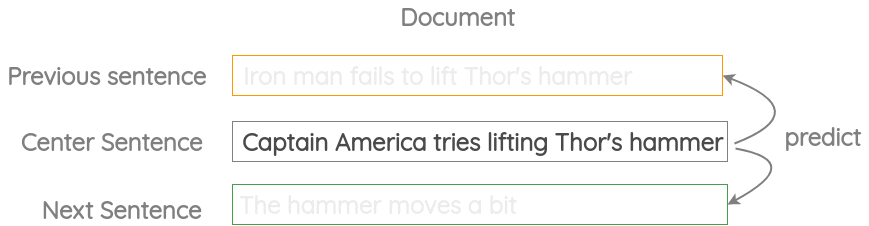
This formulation has been used in the Skip-Thought Vectors paper.
4. Auto-regressive Language Modeling
In this formulation, we take large corpus of unlabeled text and setup a task to predict the next word given the previous words. Since we already know what word should come next from the corpus, we don’t need manually-annotated labels.

For example, we could setup the task as left-to-right language modeling by predicting next words given the previous words.
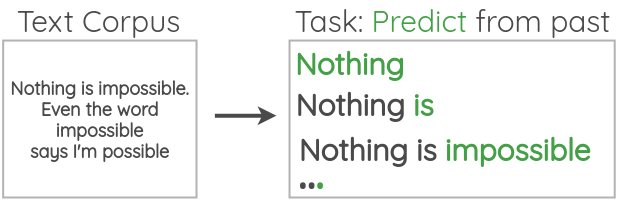
We can also formulate this as predicting the previous words given the future words. The direction will be from right to left.

This formulation has been used in many papers ranging from n-gram models to neural network models such as Neural Probabilistic Language Model(Bengio et al., 2003) to GPT.
5. Masked Language Modeling
In this formulation, words in a text are randomly masked and the task is to predict them. Compared to the auto-regressive formulation, we can use context from both previous and next words when predicting the masked word.

This formulation has been used in the BERT, RoBERTa and ALBERT papers. Compared to the auto-regressive formulation, in this task, we predict only a small subset of masked words and so the amount of things learned from each sentence is lower.
6. Next Sentence Prediction
In this formulation, we take two consecutive sentences present in a document and another sentence from a random location in the same document or a different document.

Then, the task is to classify whether two sentences can come one after another or not.

It was used in the BERT paper to improve performance on downstream tasks that requires an understanding of sentence relations such as Natural Language Inference(NLI) and Question Answering. However, later works have questioned its effectiveness.
7. Sentence Order Prediction
In this formulation, we take pairs of consecutive sentences from the document. Another pair is also created where the positions of the two sentences are interchanged.

The goal is to classify if a pair of sentences are in the correct order or not.

It was used in the ALBERT paper to replace the “Next Sentence Prediction” task.
8. Sentence Permutation
In this formulation, we take a continuous span of text from the corpus and break the sentences present there. Then, the sentences positions are shuffled randomly and the task is to recover the original order of the sentences.
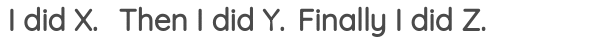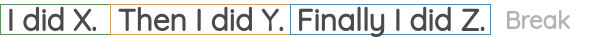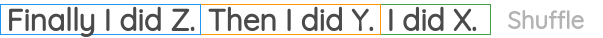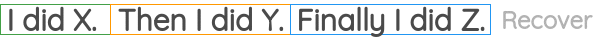
It has been used in the BART paper as one of the pre-training tasks.
9. Document Rotation
In this formulation, a random token in the document is chosen as the rotation point. Then, the document is rotated such that this token becomes the starting word. The task is to recover the original sentence from this rotated version.

It has been used in the BART paper as one of the pre-training tasks. The intuition is that this will train the model to identify the start of a document.
10. Emoji Prediction
This formulation was used in the DeepMoji paper and exploits the idea that we use emoji to express the emotion of the thing we are tweeting. As shown below, we can use the emoji present in the tweet as the label and formulate a supervised task to predict the emoji when given the text.
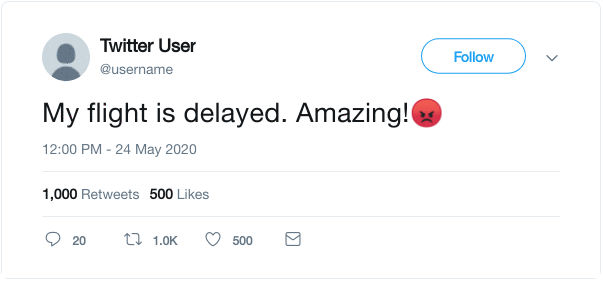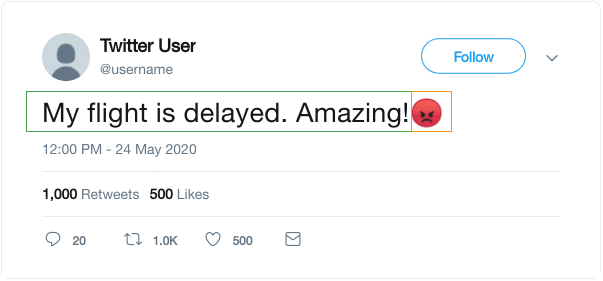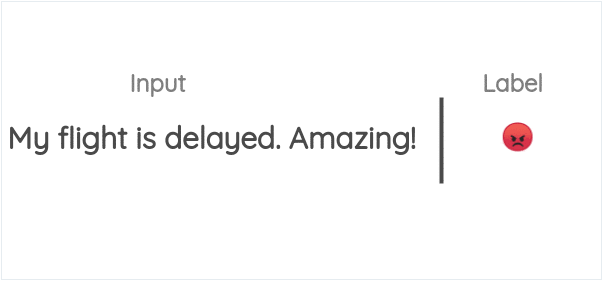
Authors of DeepMoji used this concept to perform pre-training of a model on 1.2 billion tweets and then fine-tuned it on emotion-related downstream tasks like sentiment analysis, hate speech detection and insult detection.
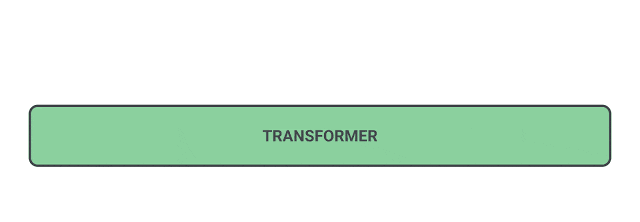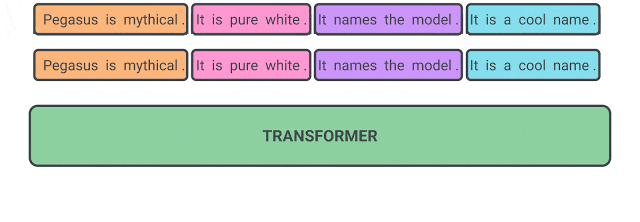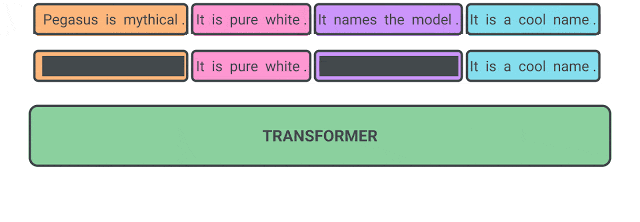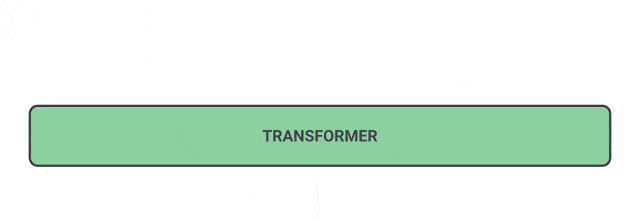
11. Gap Sentence Generation
This pretext task was proposed in the PEGASUS paper. The pre-training task was specifically designed to improve performance on the downstream task of abstractive summarization.
The idea is to take a input document and mask the important sentences. Then, the model has to generate the missing sentences concatenated together.
References
- Ryan Kiros, et al. “Skip-Thought Vectors”
- Tomas Mikolov, et al. “Efficient Estimation of Word Representations in Vector Space”
- Alec Radford, et al. “Improving Language Understanding by Generative Pre-Training”
- Jacob Devlin, et al. “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”
- Yinhan Liu, et al. “RoBERTa: A Robustly Optimized BERT Pretraining Approach”
- Zhenzhong Lan, et al. “ALBERT: A Lite BERT for Self-supervised Learning of Language Representations”
- Mike Lewis, et al. “BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension”
- Bjarke Felbo, et al. “Using millions of emoji occurrences to learn any-domain representations for detecting sentiment, emotion and sarcasm”