A Visual Guide to Regular Expression
It’s a common task in NLP to either check a text against a pattern or extract parts from the text that matches a certain pattern. A regular expression or “regex” is a powerful tool to achieve this.
While powerful, regex can feel daunting as it comes with a lot of features and sub-parts that you need to remember.
In this post, I will illustrate the various concepts underlying regex. The goal is to help you build a good mental model of how a regex pattern works.
Mental Model
Let’s start with a simple example where we are trying to find the word ‘cool’ in the text.

With regex, we could simply type out the word ‘cool’ as the pattern and it will match the word.
'cool'While regex matched our desired word ‘cool’, the way it operates is not at the word level but the character level. This is the key idea.
Key Idea: Regex works at the character-level, not word-level.

The implication of this is that the regex r'cool' would match the following sentences as well.

Basic Building Blocks
Now that we understand the key idea, let’s understand how we can match simple characters using regex.
a. Specific character
We can simply specify the character in the regular expression and it will match all instances in the text.
For example, a regular expression given below will match all instances of ‘a’ in the text. You can use any of the small and capital alphabets.
'a'
You can also use any digits from 0 to 9 and it will work as well.
'3'
Note that regex is case-sensitive by default and thus the following regex won’t match anything.
'A'
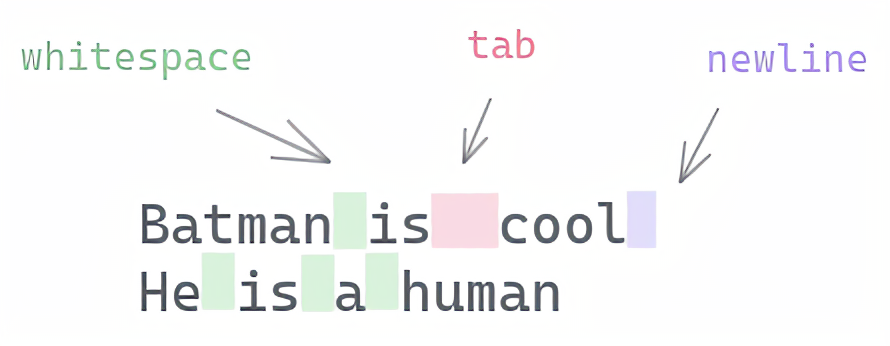
b. White space character
We can detect special characters such as whitespace and newlines using special escape sequences.

Besides the common ones above, we have:
- \r for carriage return
- \f for form feed
- \e for escape
c. Special sequences
Regex provides a bunch of built-in special symbols that can match a group of characters at once. These begin with backslash \.
Pattern: \d
It matches any single-digit number between 0 to 9.

Notice that matches are single digit. So we have 4 different matches below instead of a single number 18.04.

Pattern: \s
It matches any whitespace character (space, tab or newline).
Pattern: \w
It matches any of the small alphabets(a to z), capital alphabets(A to Z), digits (0 to 9), and underscore.

Pattern: .
It matches any character except the new line ().

import re
>>> re.findall(r'.', 'line 1\nline2')
['l', 'i', 'n', 'e', ' ', '1', 'l', 'i', 'n', 'e', '2']Pattern: Negations
If you use the capitalized versions of the patterns above, they act as negation.
For example, if “ matched any digits from 0 to 9, then”” will match anything except “0 to 9”.

d. Character sets
These are patterns starting with [ and ending with ] and specify the characters that should be matched enclosed by brackets.
For example, the following pattern matches any of the characters ‘a’, ‘e’, ‘i’, ‘o’, and ‘u’.

You can also replicate the functionality of \d using the below pattern. It will match any digits between 0 to 9.
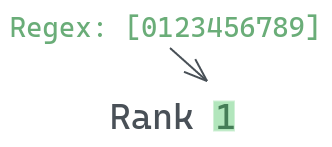
Instead of specifying all the digits, we can use - to specify only start and end digits. So, instead of [0123456789], we can do:

For example, [2-4] can be used to match any digits between 2 to 4 i.e. (2 or 3 or 4).

You can even use the special characters we learned previously inside the brackets. For example, you can match any digit from 0 to 9 or whitespace as:
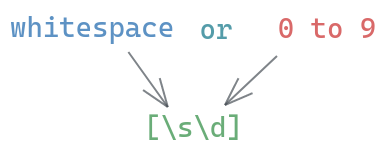
Below, I have listed some useful common patterns and what they mean.

e. Anchors
Regex also has special handlers to make the pattern only match if it’s at the start or end of the string.
We can use the ^ anchor to match patterns only at the start of a line. For example:

Similarly, we can use the $ anchor after the character to match patterns only if it’s the end of the line. For example:

f. Escaping metacharacters
Consider a case where we want to exactly match the word “Mr. Stark”.
If we write a regex like Mr. Stark, then it will have an unintended effect. Since we know dot has a special meaning in a regex.

So, we should always escape the special metacharacters like ., $ etc. if our goal is to match the exact character itself.

Here is the list of metacharacters that you should remember to escape if you’re using them directly.
^ $ . * + ? { } [ ] \ | ( )Repetition of basic blocks
Now that we can pattern match any characters, we could repeat things and start building more complicated patterns.
a. Naive repetition
Using only what we have learned so far, a naive way would be to just repeat the pattern. For example, we can match two-digit numbers by just repeating the character-level pattern.
\d\d
b. Quantifiers
Regex provides special quantifiers to specify different types of repetition for the character preceding it.
i. Fixed repetition
We can use the {...} quantifier to specify the number of times a pattern should repeat.

For example, the previous pattern for matching 2-digit number can be recreated as:

You can also specify a range of repetitions using the same quantifier. For example, to match from 2-digit to 4-digit numbers, we could use the pattern:
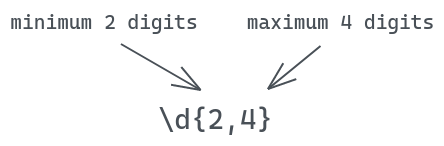
When applied to a sentence, it will match both 4-digit and 2-digit numbers.

There should not be any space between minimum and maximum count For example, \d{2, 4} doesn’t work.
ii. Flexible quantifiers
Regex also provides quantifiers “*“,”+” and “?” using which you can specify flexible repetition of a character.
0 or 1 times:
?
The?quantifier matches the previous character if it repeats 0 or 1 times. This can be useful to make certain parts optional. It is equivalent to{0,1}.
For example, let’s say we want to match both the word “sound” and “sounds” where “s” is optional. Then, we can use the
?quantifier that matches if a character repeats 0 or 1 times.
one or more times:
+
The+quantifier matches the previous character if it repeats 1 or more times. It is equivalent to{1,}.For example, we could find numbers of any arbitrary length using the regex
\d+.
zero or more times:
*
The*quantifier matches the previous character if it repeats zero or more times. It is equivalent to{0,}.
Usage in Python
Python provides a module called “re” in the standard library to work with regular expression.
Need for raw strings
To specify a regular expression in Python, we precede it with r to create raw strings.
pattern = r'\d'To understand why we precede with r, let’s try printing the expression \t without r.
pattern = '\t'
print(pattern)You can see how when we don’t use raw string, the string \t is treated as the escape character for tab by Python.
Now let’s convert it into raw string. We get back whatever we specified.
pattern = r'\t'
print(pattern)
\tUsing re module
To use re module, we can start by importing the re module as:
import re1. re.findall
This function allows us to get all the matches as a list of strings.
import re
re.findall(r'\d', '123456')['1', '2', '3', '4', '5', '6']2. re.match
This function searches for a pattern at the beginning of the string and returns the first occurrence as a match object. If the pattern is not found, it returns None.
import re
match = re.match(r'batman', 'batman is cool')
print(match)<re.Match object; span=(0, 6), match='batman'>
With the match object, we can get the matched text as
print(match.group())batmanIn a case where our pattern is not at the start of the sentence, we will not get any match.
import re
match = re.match(r'batman', 'The batman is cool')
print(match)None3. re.search
This function also finds the first occurrence of a pattern but the pattern can occur anywhere in the text. If the pattern is not found, it returns None.
import re
match = re.search(r'batman', 'the batman is cool')
print(match.group())batmanReferences
- A.M. Kuchling, “Regular Expression HOWTO - Python 3.9.0 documentation”