Zero Shot Learning for Text Classification
The recent release of GPT-3 got me interested in the state of zero-shot learning and few-shot learning in NLP. While most of the zero-shot learning research is concentrated in Computer Vision, there has been some interesting work in the NLP domain as well.
I will be writing a series of blog posts to cover existing research on zero-shot learning in NLP. In this first post, I will explain the paper “Train Once, Test Anywhere: Zero-Shot Learning for Text Classification” by Pushp et al. This paper from December 2017 was the first work to propose a zero-shot learning paradigm for text classification.
What is Zero-Shot Learning?
Zero-Shot Learning is the ability to detect classes that the model has never seen during training. It resembles our ability as humans to generalize and identify new things without explicit supervision.
For example, let’s say we want to do sentiment classification and news category classification. Normally, we will train/fine-tune a new model for each dataset. In contrast, with zero-shot learning, you can perform tasks such as sentiment and news classification directly without any task-specific training.
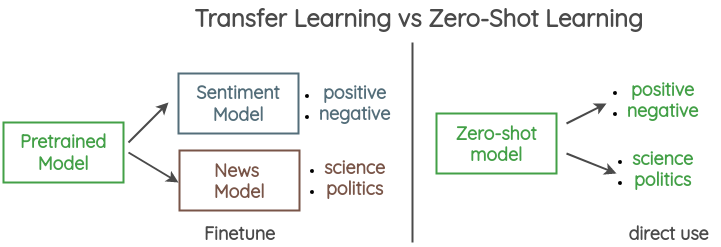
Train Once, Test Anywhere
In the paper, the authors propose a simple idea for zero-shot classification. Instead of classifying texts into X classes, they re-formulate the task as a binary classification to determine if a text and a class are related or not.
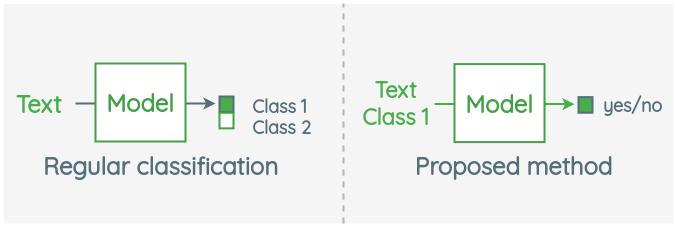
Let’s understand their formulation and end-to-end process in more detail now.
1. Data Preparation
The authors crawled 4.2 million news headlines from the web and used the SEO tags for the news article as the labels. After crawling, they got total 300,000 unique tags as the labels. We can see how troublesome it would have been if we had to train a supervised model on 300,000 classes.
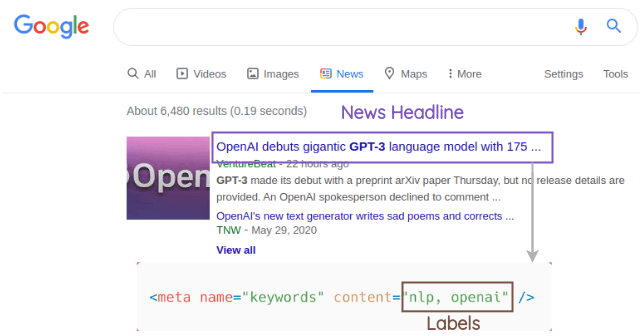
Each headline was truncated to 28 words and anything shorter was padded.
2. Word Embedding
The paper uses word2vec pre-trained on Google News as the word embeddings for both the sentences as well as the labels.
3. Model Architecture
The paper proposes three different architecture to learn the relation between sentence and label embeddings.
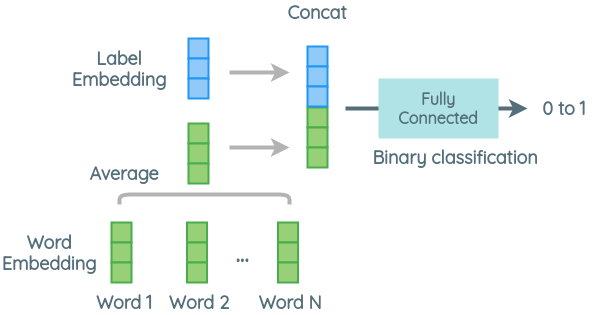
a. Architecture 1
In this architecture, we take the mean of word embeddings in the sentence as the sentence embedding and concatenate it with the label embedding. This vector is then passed through a fully connected layer to classify if the sentence and label are related or not.
b. Architecture 2
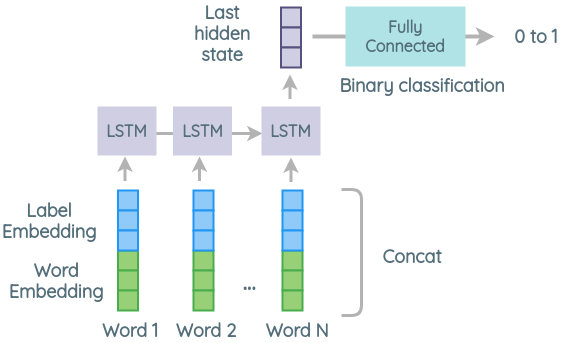
In this architecture, instead of taking the mean, the word embeddings are passed through an LSTM and the last hidden state of the network is treated as the sentence vector. It is concatenated with the word vector of the label and then passed through a fully connected layer to classify if the sentence and label are related or not.
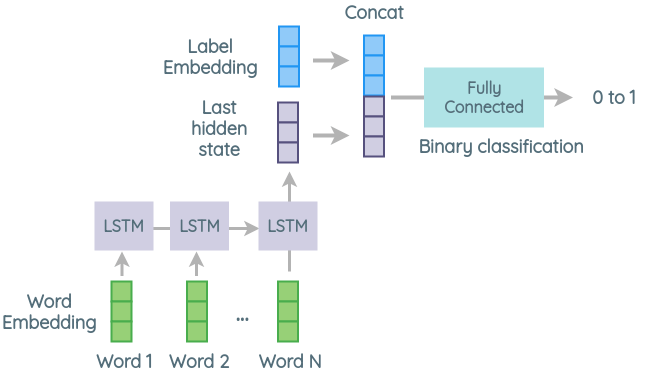
c. Architecture 3
In this architecture, the embedding of each word in the sentence is concatenated with the embedding of the label. This combined embedding is passed through an LSTM and the last hidden state of the network is taken. It is then passed through a fully connected layer to classify if the sentence and label are related or not.
4. Training
Using the crawled news headlines dataset, each headline is paired with 50% actual labels and 50% randomly selected unrelated labels. Then the model is trained using above 3 architectures with a binary cross-entropy loss with Adam optimizer.
In the paper, they achieve the highest accuracy of 74% on the binary classification task with Architecture 3, followed by 72.6% on architecture 2 and 72% on architecture 1 on the separated test set of the news headlines dataset.
5. Zero-Shot Classification
Now, taking the trained model that can compute relatedness score of sentences with labels, the authors tested its generalization capability to unseen datasets and labels.
The authors tested their model on a hold-out test set containing labels not present during training. They achieve 78%, 76% and 81% accuracy on the binary classification task with architecture 1, 2 and 3 respectively.
UCI News Aggregator Dataset:
In this dataset, there are 420,000 sentences with 4 labels: technology, business, medicine and entertainment. They propose a heuristic called category tree where they expand each label with related words. The process is as follows:- Take the unseen labels and add a few words related to this concept. For example, related words for business can be ‘finance’ and ‘revenue’.

- To predict the class(category) for a sentence, they predict the relatedness of the sentence to related words under that category and take their mean as the final relatedness.
- The classes which had mean relatedness probability above a threshold are assumed as the predicted classes. This threshold is a hyperparameter and the paper uses 0.5 as the threshold.
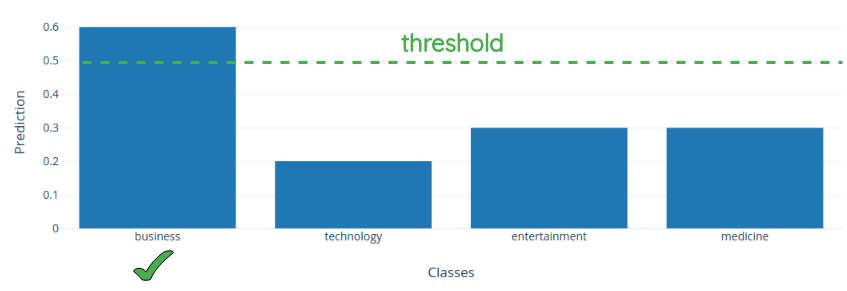
The authors tested this process on the entire dataset and achieved 61.73%, 63% and 64.21% accuracy. In comparison, the supervised methods achieve 94.75% accuracy. The result is still interesting because without even training on a single sample, it achieves better than random accuracy.
Tweet Classification:
This dataset has 1993 sentences with 6 labels: business, health, politics, sports, technology and entertainment. The authors tested their method over the whole dataset using a threshold of 0.5 and a category tree expansion with 3 related words and achieved 64.5% accuracy with Architecture 3. In comparison, a supervised method such as multinominal naive bayes trained on the whole dataset can get 78% accuracy.
Conclusion
The paper proposes some really simple but clever techniques to learn the relationship between sentences and labels and achieves better than random accuracy on unseen datasets and labels. Since this was proposed in the pre-transformer era, it can be interesting to try these ideas with recent models.
References
- Pushpankar Kumar Pushp, et al. “Train Once, Test Anywhere: Zero-Shot Learning for Text Classification”