A Visual Survey of Data Augmentation in NLP
Unlike Computer Vision where using image data augmentation is standard practice, augmentation of text data in NLP is pretty rare. Trivial operations for images such as rotating an image a few degrees or converting it into grayscale doesn’t change its semantics. This presence of semantically invariant transformation made augmentation an essential toolkit in Computer Vision research.
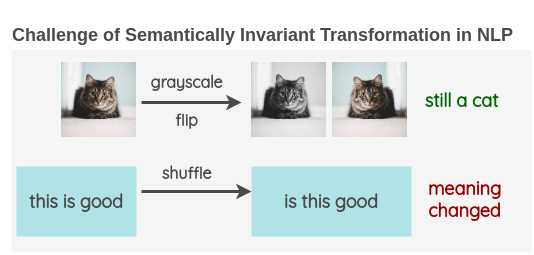
I was curious if there were attempts at developing augmentation techniques for NLP and explored the existing literature. In this post, I will give an overview of the current approaches for text data augmentation based on my findings.
NLP Data Augmentation Techniques
1. Lexical Substitution
This line of work tries to substitute words present in a text without changing the meaning of the sentence.
a. Thesaurus-based substitution
In this technique, we take a random word from the sentence and replace it with its synonym using a Thesaurus. For example, we could use the WordNet database for English to look up the synonyms and then perform the replacement. It is a manually curated database with relations between words.
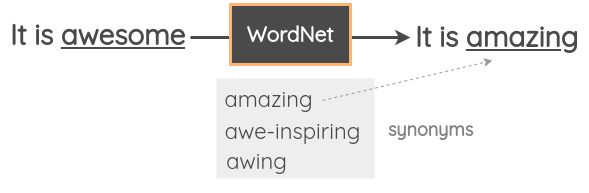
Zhang et al. (2015) used this technique in their paper “Character-level Convolutional Networks for Text Classification”. Mueller and Thyagarajan (2016) used a similar strategy to generate additional 10K training examples for their sentence similarity model. This technique was also used by Wei and Zou (2019) as one of the techniques in their pool of four random augmentations in the “Easy Data Augmentation” paper.
For implementation, NLTK provides a programmatic access to WordNet. You can also use the TextBlob API. Additionally, there is a database called PPDB (Ganitkevitch et al. (2013)) containing millions of paraphrases that you can download and use programmatically.
b. Word-Embeddings Substitution
In this approach, we take pre-trained word embeddings such as Word2Vec, GloVe, FastText, Sent2Vec, and use the nearest neighbor words in the embedding space as the replacement for some word in the sentence.
Jiao et al. (2020) used this technique with GloVe embeddings to improve the generalization of their language model on downstream tasks. Wang and Yang (2015) used it to augment tweets needed to learn a topic model.

For example, you can replace the word with the 3-most similar words and get three variations of the text.
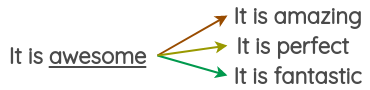
It’s easy to use packages like Gensim to access pre-trained word vectors and get the nearest neighbors. For example, here we find the synonyms for the word ‘awesome’ using word vectors trained on tweets.
# pip install gensim
import gensim.downloader as api
model = api.load('glove-twitter-25')
model.most_similar('awesome', topn=5)You will get back the 5 most similar words along with the cosine similarities.
[('amazing', 0.9687871932983398),
('best', 0.9600659608840942),
('fun', 0.9331520795822144),
('fantastic', 0.9313924312591553),
('perfect', 0.9243415594100952)]c. Masked Language Model
Transformer models such as BERT, ROBERTA, and ALBERT have been trained on a large amount of text using a pretext task called “Masked Language Modeling” where the model has to predict masked words based on the context.
This can be used to augment some text. For example, we could use a pre-trained BERT model, mask some parts of the text, and ask the BERT model to predict the token for the mask.
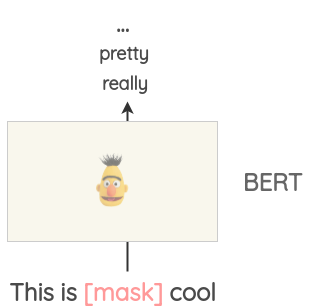
Thus, we can generate variations of a text using the mask predictions. Compared to previous approaches, the generated text is more grammatically coherent as the model takes context into account when making predictions.
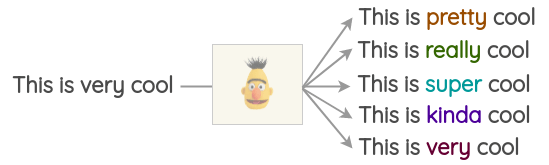
This is easy to implement with open-source libraries such as transformers by Hugging Face. You can set the token you want to replace with <mask> and generate predictions.
from transformers import pipeline
nlp = pipeline('fill-mask')
nlp('This is <mask> cool')[{'score': 0.515411913394928,
'sequence': '<s> This is pretty cool</s>',
'token': 1256},
{'score': 0.1166248694062233,
'sequence': '<s> This is really cool</s>',
'token': 269},
{'score': 0.07387523353099823,
'sequence': '<s> This is super cool</s>',
'token': 2422},
{'score': 0.04272908344864845,
'sequence': '<s> This is kinda cool</s>',
'token': 24282},
{'score': 0.034715913236141205,
'sequence': '<s> This is very cool</s>',
'token': 182}]However, one caveat of this method is that deciding which part of the text to mask is not trivial. You will have to use heuristics to decide the mask, otherwise, the generated text might not retain the meaning of the original sentence.
Garg and Ramakrishnan (2020) use this idea for generating adversarial examples for text classification.

d. TF-IDF based word replacement
This augmentation method was proposed by Xie et al. (2019) in the Unsupervised Data Augmentation paper. The basic idea is that words that have low TF-IDF scores are uninformative and thus can be replaced without affecting the ground-truth labels of the sentence.

The words that replace the original word are chosen by calculating TF-IDF scores of words over the whole document and taking the lowest ones. You can refer to the code implementation for this in the original paper.
2. Back Translation
In this approach, we leverage machine translation to paraphrase a text while retraining the meaning. Xie et al. (2019) used this method to augment the unlabeled text and learn a semi-supervised model on IMDB dataset with only 20 labeled examples. Their model outperformed the previous state-of-the-art model trained on 25,000 labeled examples.
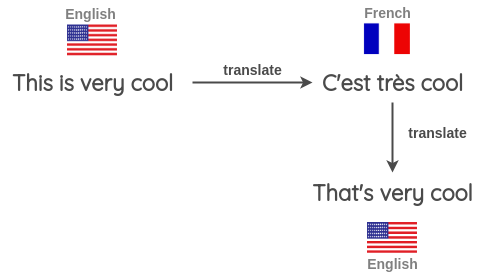
The back-translation process is as follows:
- Take some sentence (e.g. in English) and translate to another Language e.g. French
- Translate the French sentence back into an English sentence
- Check if the new sentence is different from our original sentence. If it is, then we use this new sentence as an augmented version of the original text.
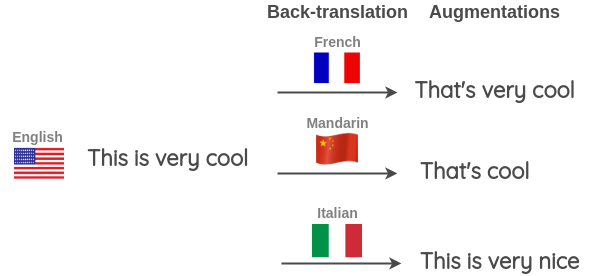
You can also run back-translation using different languages at once to generate more variations. As shown below, we translate an English sentence to a target language and back again to English for three target languages: French, Mandarin, and Italian.
This technique was also used in the 1st place solution for the “Toxic Comment Classification Challenge” on Kaggle. The winner used it for both training-data augmentations as well as during test-time where the predicted probabilities for English sentence along with back-translation using three languages(French, German, Spanish) were averaged to get the final prediction.
For the implementation of back-translation, you can use TextBlob. Alternatively, you can also use Google Sheets to apply Google Translate for free. You can also use MarianMT for back-translation.
3. Text Surface Transformation
These are simple pattern matching transformations applied using regex and was introduced by Coulombe (2018).
In the paper, he gives an example of transforming verbal forms from contraction to expansion and vice versa. We can generate augmented texts by applying this.

Since the transformation should not change the meaning of the sentence, we can see that this can fail in case of expanding ambiguous verbal forms like:
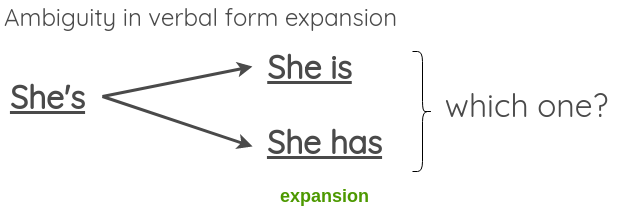
To resolve this, the paper proposes that we allow ambiguous contractions but skip ambiguous expansion.
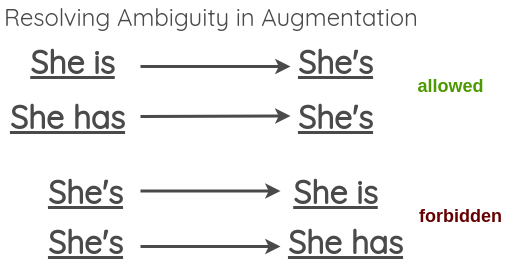
You can find a list of contractions for the English language here. For expansion, you can use the contractions library in Python.
4. Random Noise Injection
The idea of these methods is to inject noise in the text so that the model trained is robust to perturbations.
a. Spelling error injection
In this method, we add spelling errors to some random word in the sentence. These spelling errors can be added programmatically or using a mapping of common spelling errors such as this list for English.

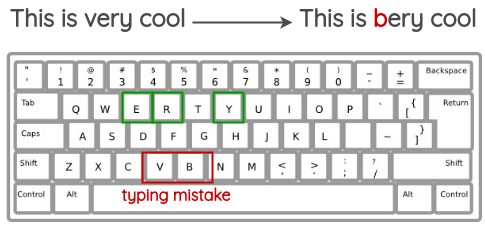
b. QWERTY Keyboard Error Injection
This method tries to simulate common errors that happen when typing on a QWERTY layout keyboard due to keys that are very near to each other. The errors are injected based on keyboard distance.
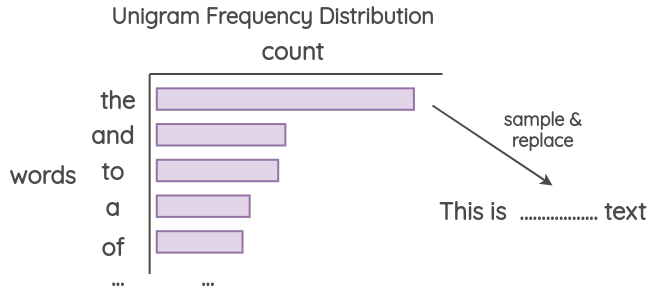
c. Unigram Noising
This method has been used by Xie et al. (2017) and Xie et al. (2019). The idea is to perform replacement with words sampled from the unigram frequency distribution. This frequency is basically how many times each word occurs in the training corpus.
d. Blank Noising
This method has been proposed by Xie et al. (2017). The idea is to replace a random word with a placeholder token. The paper uses “_” as the placeholder token. In the paper, they use it as a way to avoid overfitting on specific contexts as well as a smoothing mechanism for the language model. The technique helped improve perplexity and BLEU scores.

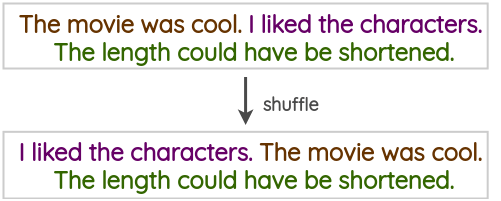
e. Sentence Shuffling
This is a naive technique where we shuffle sentences present in a training text to create an augmented version.
f. Random Insertion
This technique was proposed by Wei and Zou (2019) in their paper “Easy Data Augmentation”. In this technique, we first choose a random word from the sentence that is not a stop word. Then, we find its synonym and insert that into a random position in the sentence.

g. Random Swap
This technique was also proposed by Wei and Zou (2019) in their paper “Easy Data Augmentation”. The idea is to randomly swap any two words in the sentence.

h. Random Deletion
This technique was also proposed by Wei and Zou (2019) in their paper “Easy Data Augmentation”. In this, we randomly remove each word in the sentence with some probability p.

5. Instance Crossover Augmentation
This technique was introduced by Luque (2019) in his paper on sentiment analysis for TASS 2019. It is inspired by the chromosome crossover operation that happens in genetics.
In the method, a tweet is divided into two halves and two random tweets of the same polarity(i.e. positive/negative) have their halves swapped. The hypothesis is that even though the result will be ungrammatical and semantically unsound, the new text will still preserve the sentiment.
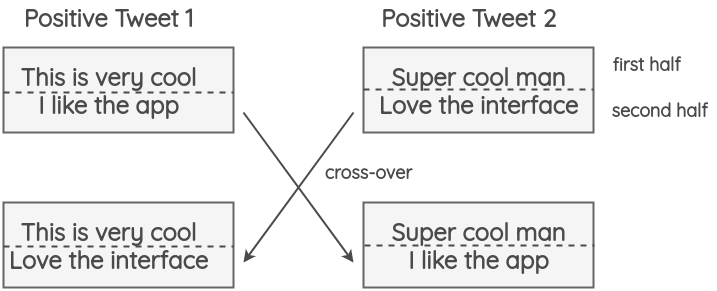
This technique had no impact on the accuracy but helped with the F1 score in the paper showing that it helps minority classes such as the Neutral class with fewer tweets.

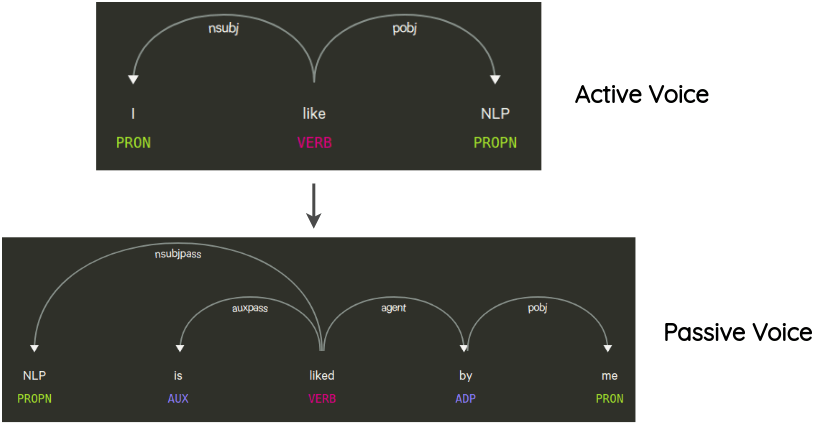
6. Syntax-tree Manipulation
This technique has been used in the paper by Coulombe (2018). The idea is to parse and generate the dependency tree of the original sentence, transform it using rules, and generate a paraphrased sentence.
For example, one transformation that doesn’t change the meaning of the sentence is the transformation from active voice to the passive voice of sentence and vice versa.
7. MixUp for Text
Mixup is a simple yet effective image augmentation technique introduced by Zhang et al. (2018). The idea is to combine two random images in a mini-batch in some proportion to generate synthetic examples for training. For images, this means combining image pixels of two different classes. It acts as a form of regularization during training.

Bringing this idea to NLP, Guo et al. (2019) modified Mixup to work with text. They propose two novel approaches for applying Mixup to text:
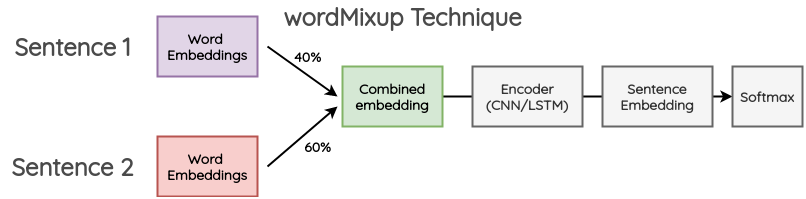
a. wordMixup:
In this method, two random sentences in a mini-batch are taken and they are zero-padded to the same length. Then, their word embeddings are combined in some proportion. The resulting word embedding is passed to the usual flow for text classification. The cross-entropy loss is calculated for both the labels of the original text in the given proportion.
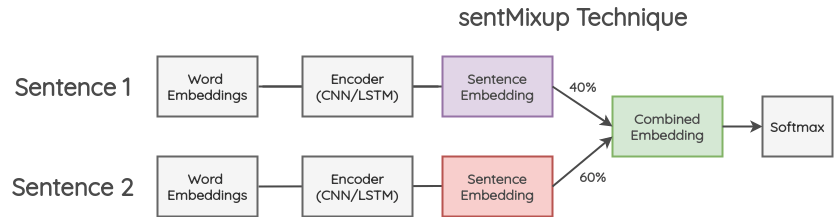
b. sentMixup:
In this method, two sentences are taken and they are zero-padded to the same length. Then, their word embeddings are passed through LSTM/CNN encoder and we take the last hidden state as sentence embedding. These embeddings are combined in a certain proportion and then passed to the final classification layer. The cross-entropy loss is calculated based on both the labels of original sentences in the given proportion.
8. Generative Methods
This line of work tries to generate additional training data while preserving the class label.
a. Conditional Pre-trained Language Models
This technique was first proposed by Anaby-Tavor et al. (2019). A recent paper from Kumar et al. (2021) evaluated this idea across multiple transformer-based pre-trained models. The problem formulation is as follows:
- Prepend the class label to each text in your training data
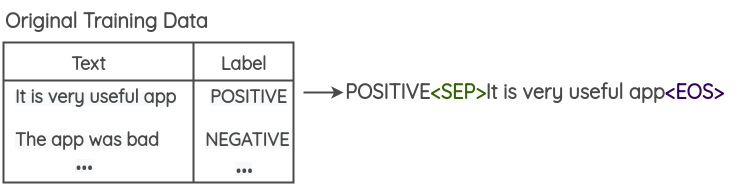
- Finetune a large pre-trained language model(BERT/GPT2/BART) on this modified training data. For GPT2, the fine-tuning task is generation while for BERT, the goal would be a masked token prediction.

- Using the fine-tuned language model, new samples can be generated by using the class label and a few initial words as the prompt for the model. The paper uses 3 initial words of each training text and also generates one synthetic example for each point in the training data.

Implementation
Libraries like nlpaug and textattack provide simple and consistent API to apply the above NLP data augmentation methods in Python. They are framework agnostic and can be easily integrated into your pipeline.
Conclusion
My takeaway from the literature review is that many of these NLP augmentation methods are very task-specific and their impact on performance has been studied for some particular use-cases only. It would be an interesting research to systematically compare these methods and analyze their impact on performance for many tasks.
References
Citation
@online{chaudhary2020,
author = {Chaudhary, Amit},
title = {A {Visual} {Survey} of {Data} {Augmentation} in {NLP}},
date = {2020-05-16},
url = {https://amitness.com/posts/data-augmentation-for-nlp.html},
langid = {en}
}