Zero-shot Text Classification With Generative Language Models
In my last post, we explored a contrastive learning approach to zero-shot text classification. In this post, we will explore a different approach based on text generation. This approach was proposed by Puri et al. in their paper “Zero-shot Text Classification With Generative Language Models”. The paper was also presented in the “3rd Workshop on Meta-Learning” at NeurIPS 2019.
The goal of zero-shot text classification is to design a general and flexible approach that can generalize to new classification tasks without the need for task-specific classification heads. > Build a text classification model that can classify classes on a new dataset it was never trained on.
Paper Idea
In the paper, the authors reformulate text classification as a text generation problem. Instead of classifying a text into X classes, the model needs to generate the correct class when given a text and the classes in a multiple-choice question answering format. Both the input and the output of the model are in natural language.

Let’s understand how the authors implemented this idea in a step-by-step process:
Phase 1: Pre-training
As seen in the formulation above, we need to teach GPT-2 to pick the correct class when given the problem as a multiple-choice problem. The authors teach GPT-2 to do this by fine-tuning on a simple pre-training task called title prediction.
1. Gathering Data for Weak Supervision
In the original GPT-2 paper, the training data was prepared by scraping outbound web links that were submitted or commented on Reddit and had a minimum of 3 karma score.
In the current paper, the authors build upon this idea with the OpenWebText dataset. Since we can know the subreddit the link was posted in and the submission title the user used, this metadata can be collected and used as the supervision signal.
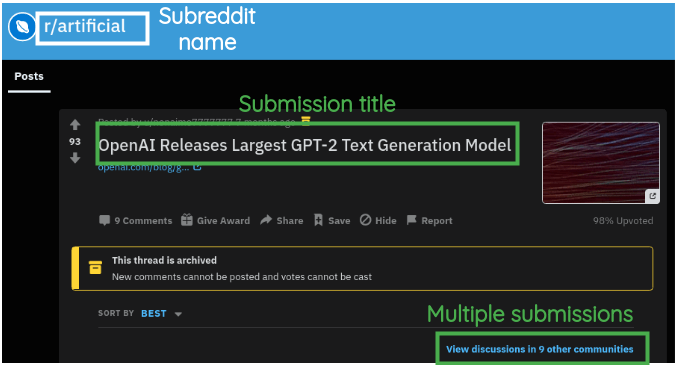
For multiple submissions of the same link, subreddits and submission titles can be aggregated. Thus, we have pairs of webpage text, submission title, and subreddit name as annotations.
| Scraped Text | Submission Title | Subreddit |
|---|---|---|
| We’ve trained a large-scale unsupervised language model which generates coherent paragraphs of text, achieves state-of-the-art performance on many … | OpenAI Releases Largest GPT-2 Text Generation Model | r/artificial |
| … | … | … |
The authors found subreddit prediction didn’t generalize well and so they use submission title in their experiments.
2. Multiple choice question answering format
To feed the annotated data into GPT-2, the authors prepared 26 different multiple-choice question format. A random question format is sampled during training.

Now for each document, we randomly choose between 2 to 15 titles. One title is correct for that document while all others are random titles.
We also add regularization by replacing a title with “none of the above” 50% of the time. And the correct title is also replaced with “none of the above” with a probability 1/(number of titles). Such noise can help train the model to choose “none of the above” if none of the choices match the content.
As shown below, the titles are placed after the question as a comma-separated list.
| Question | Text | Answer |
|---|---|---|
| Which of these choices best describes the following document?: ” OpenAI Releases Largest GPT-2 Text Generation Model “,” Facebook buys Whatsapp ” | We’ve trained a large-scale … | OpenAI Releases Largest GPT-2 Text Generation Model |
The question is prepended to the document to simulate a multiple-choice question answering task and a pre-trained GPT-2 language model is fine-tuned on this dataset to learn the submission title prediction task.
Phase 2: Zero-Shot Classification
From the previous step, we have a model that has been trained on a wide variety of titles from the web and thus simulates meta-learning with N-way text classification tasks.
To test the zero-shot capabilities of the model, the authors tested it on 6 benchmark datasets without doing any finetuning.
| Dataset | Classes |
|---|---|
| SST-2 | Positive Sentiment, Negative Sentiment |
| Yelp-2 | Positive polarity, Negative polarity |
| Amazon-2 | Positive polarity, Negative polarity |
| AGNews | Science & Technology, Business, Sports, World News |
| DBPedia | Company, Mean Of Transportation, Film, Office Holder, Written Work, Animal, Natural Place, Artist, Plant, Athlete, Album, Building, Village, Educational Institution |
| Yahoo Answers | Family & Relationships, Business & Finance, Health, Society & Culture, Education & Reference, Entertainment & Music, Science & Mathematics, Computers & Internet, Sports, Politics & Government |
For each dataset, they perform the following steps:
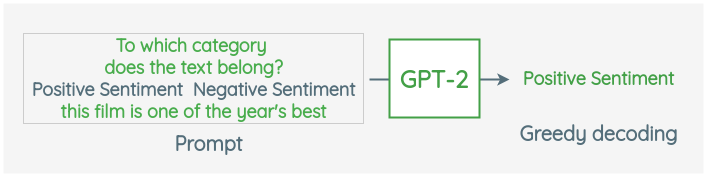
They convert the classes in each dataset into the same multiple-choice question format as pre-training and prepend it to the text. For example, for SST-2 dataset which contains movie reviews, the format would be:
Question Text Answer To which category does the text belong?:” Positive Sentiment “,” Negative Sentiment ” the film is one of the year’s best Positive Sentiment The question is prepended to the text and passed to GPT-2 as a prompt. Then we use greedy sampling to generate the output from GPT-2 and compare it with the actual class. Accuracy for each dataset is calculated.
Results and Insights
Even without access to the training data, the model was able to achieve up to 45% improvement in classification accuracy over random and majority class baselines.
For sentiment datasets such as SST-2, Amazon-2, and Yelp-2, the larger size 335M GPT-2 model has a significant improvement over the random and majority class baselines. Zero-shot performance is still below direct finetuning and the SOTA held by XLNET.
Model SST-2 Amazon-2 Yelp-2 Random Guess 50.6 52.9 50.4 Majority Class 49.9 49.3 49.2 Zero-Shot 355M All Data 62.5 80.2 74.7 355M Finetuned 93.23 97.115 94.479 SOTA(XLNET, 2019) 96.8 97.6 98.45 Increasing the model size from 117M to 355M parameters leads to better zero-shot performance on downstream tasks.
Model SST-2 Amazon-2 Yelp-2 Zero-Shot 117M All Data 51.8 50.3 50.1 Zero-Shot 355M All Data 62.5 80.2 74.7 When pretraining is done on the only 1/4th of the total data, it leads to a decrease in overall performance. This shows that pretraining across a diverse set of tasks is needed and a larger dataset provides that.
Model SST-2 Amazon-2 Yelp-2 Zero-Shot 355M 1/4 Data 61.7 64.5 58.5 Zero-Shot 355M All Data 62.5 80.2 74.7 For datasets like DBPedia, AGNews, and Yahoo Answer with many classes, the model performs noticeably better than random but struggles to break past 50% accuracy. The authors say this could be because the model can identify unlikely classes, but struggle to choose between most plausible options due to lack of any supervision. Also, performance is better with less data than with full dataset pretraining for them.
Model AGNews DBPedia Yahoo Answers Random Guess 27.4 7.27 10.2 Majority Class 25.3 7.6 9.9 Zero-Shot 117M All Data 40.2 39.6 26.1 Zero-Shot 355M 1/4 Data 68.3 52.5 52.2 Zero-Shot 355M All Data 65.5 44.8 49.5 355M Finetuned 94.87 99.0 72.79 SOTA 95.51 99.38 76.26 The authors point out that there were controllability issues because GPT-2 was generating answers which were not a valid class. For example, for the yahoo answers dataset, valid classes are “education & reference” and “science and mathematics’. But, the model sometimes mixed these two and generated ‘education and mathematics’. This problem diminished as the model size was increased to 355M and full data was used.

- Another issue with the model was the generation of an empty string and rearranging the tokens of a valid answer e.g. “Positive Sentiment” -> “Sentiment Positive”. This problem was frequent with top-k and top-p sampling and rare with greedy decoding, and so the authors chose greedy decoding.

Conclusion
The paper provides a good overview of the method and challenges of using generative language models for zero-shot classification and show that natural language could be a promising meta-learning strategy for text problems.
References
- Raul Puri et al., “Zero-shot Text Classification With Generative Language Models”